2019第九周做业
| 这个做业属于哪一个课程 | C语言程序设计 |
| 这个做业的要求在哪里 | https://edu.cnblogs.com/campus/zswxy/software-engineering-class2-2018/homework/3124 |
| 我在这个课程的目标是 | 可以根据实际状况合理定义结构,可以使用结构变量与结构数组进行熟练编程。 |
| 这个做业在哪一个具体方面帮助我实现目标 | 能熟练进行结构变量的定义和初始化,熟练运用结构变量解决问题 |
| 参考文献 | C语言程序设计 |
一.基础题
6-1 按等级统计学生成绩 (20 分)
本题要求实现一个根据学生成绩设置其等级,并统计不及格人数的简单函数。
函数接口定义:算法
int set_grade( struct student *p, int n );
其中p是指向学生信息的结构体数组的指针,该结构体的定义为:编程
struct student{
int num;
char name[20];
int score;
char grade;
};
n是数组元素个数。学号num、姓名name和成绩score均是已经存储好的。set_grade函数须要根据学生的成绩score设置其等级grade。等级设置:85-100为A,70-84为B,60-69为C,0-59为D。同时,set_grade还须要返回不及格的人数。
裁判测试程序样例:数组
#include <stdio.h>
#define MAXN 10
struct student{
int num;
char name[20];
int score;
char grade;
};
int set_grade( struct student *p, int n );
int main()
{ struct student stu[MAXN], *ptr;
int n, i, count;
ptr = stu;
scanf("%d\n", &n);
for(i = 0; i < n; i++){
scanf("%d%s%d", &stu[i].num, stu[i].name, &stu[i].score);
}
count = set_grade(ptr, n);
printf("The count for failed (<60): %d\n", count);
printf("The grades:\n");
for(i = 0; i < n; i++)
printf("%d %s %c\n", stu[i].num, stu[i].name, stu[i].grade);
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例:app
10 31001 annie 85 31002 bonny 75 31003 carol 70 31004 dan 84 31005 susan 90 31006 paul 69 31007 pam 60 31008 apple 50 31009 nancy 100 31010 bob 78
输出样例:函数
The count for failed (<60): 1 The grades: 31001 annie A 31002 bonny B 31003 carol B 31004 dan B 31005 susan A 31006 paul C 31007 pam C 31008 apple D 31009 nancy A 31010 bob B
1)运行代码
int set_grade( struct student *p, int n )
{
int h=0,i;
for(i=0;i<n;i++,p++){
if(p->score>=85&&p->score<=100){
p->grade='A';
}
else if(p->score>=70&&p->score<=84){
p->grade='B';
}
else if(p->score>=60&&p->score<=69){
p->grade='C';
}
else if(p->score>=0&&p->score<=59){
p->grade='D';
h++;
}
}
return h;
}
###2)设计思路
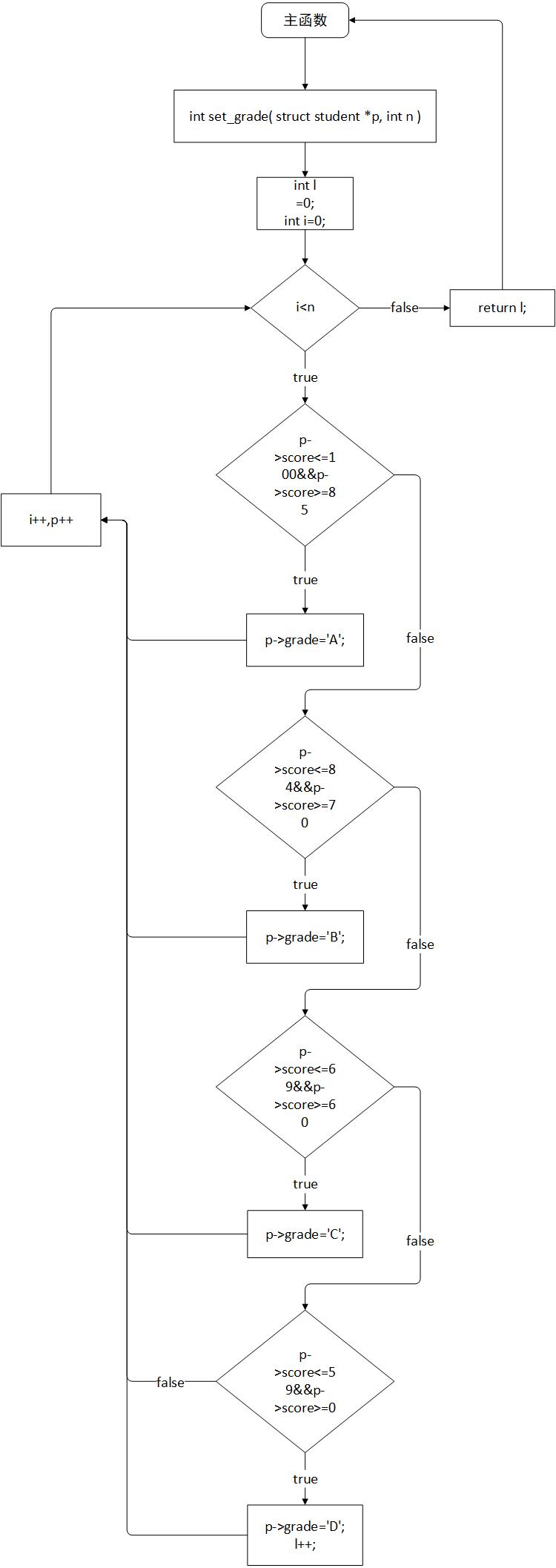
###3)本题调试过称中遇到的问题及解决办法
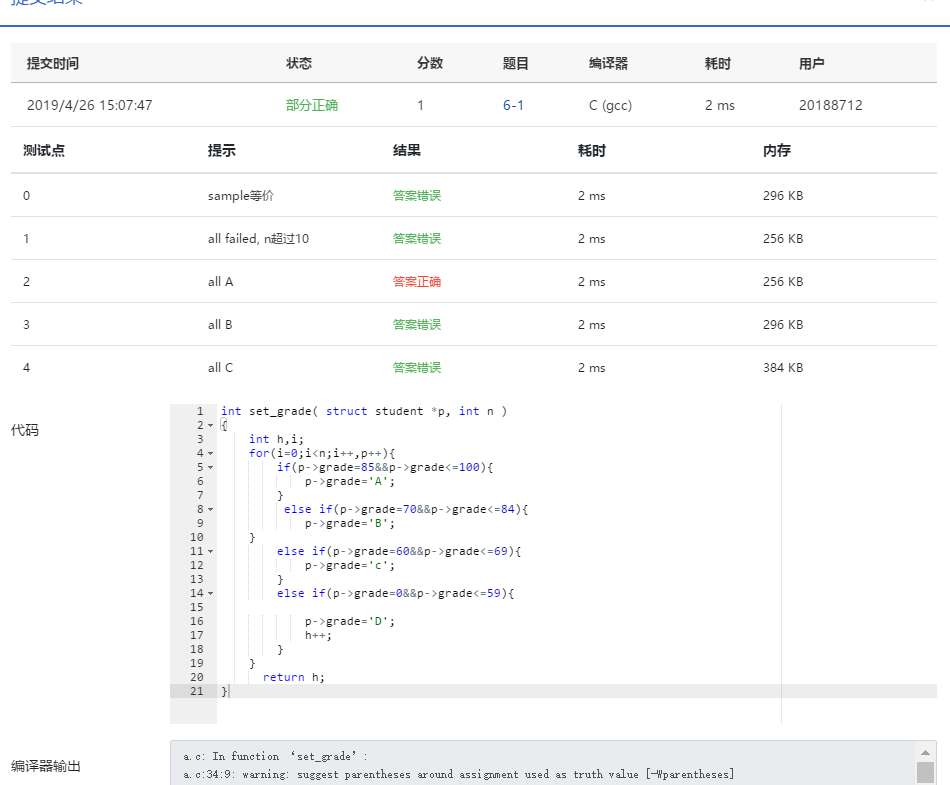
忘记给L初始化为零了,致使本身检查了不少遍都没发现错误。
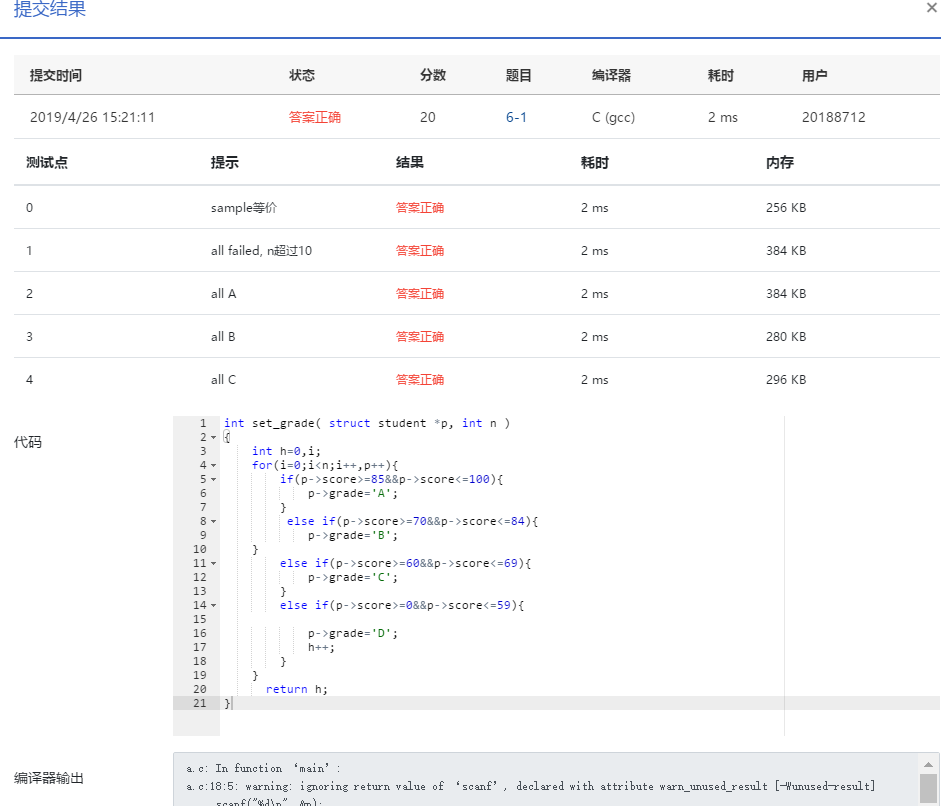
###4)运行截图
##7-1 一帮一 (15 分)
“一帮一学习小组”是中小学中常见的学习组织方式,老师把学习成绩靠前的学生跟学习成绩靠后的学生排在一组。本题就请你编写程序帮助老师自动完成这个分配工做,即在获得全班学生的排名后,在当前还没有分组的学生中,将名次最靠前的学生与名次最靠后的异性学生分为一组。
输入格式:
输入第一行给出正偶数N(≤50),即全班学生的人数。此后N行,按照名次从高到低的顺序给出每一个学生的性别(0表明女生,1表明男生)和姓名(不超过8个英文字母的非空字符串),其间以1个空格分隔。这里保证本班男女比例是1:1,而且没有并列名次。
输出格式:
每行输出一组两个学生的姓名,其间以1个空格分隔。名次高的学生在前,名次低的学生在后。小组的输出顺序按照前面学生的名次从高到低排列。
输入样例:
8
0 Amy
1 Tom
1 Bill
0 Cindy
0 Maya
1 John
1 Jack
0 Linda性能
输出样例:
Amy Jack
Tom Linda
Bill Maya
Cindy John学习
###1)实验代码
include<stdio.h>
include<string.h>
struct student{
int x;
char name[10];
};
struct zy{
char names[10];
char named[10];
};测试
int main()
{
struct student a[50];
struct zy b[50];
int n,i;
scanf("%d",&n);
for(i=0;i<n;i++){
scanf("%d %s",&a[i].x,a[i].name);
}
for(i=0;i<n/2;i++){
strcpy(b[i].names,a[i].name);
}
//再从全班后一半,从最后一位开始循环和第一位组员比较性别
for(int i=0;i<n/2;i++){
for(int j=n-1;j>=n/2;j--){
//若性别不一样,且没有和别的组员匹配
if(a[i].x!=a[j].x&&a[j].x!=5){
//将姓名储存在第二位组员
strcpy(b[i].named,a[j].name);
//若已经匹配了,则改变性别
a[j].x=5;
//匹配完后,跳出内循环,以避免又和下一位异性匹配
break;
}
}
}
for(int i=0;i<n/2;i++){
printf("%s %s\n",b[i].names,b[i].named);
}
}设计
###2)设计思路 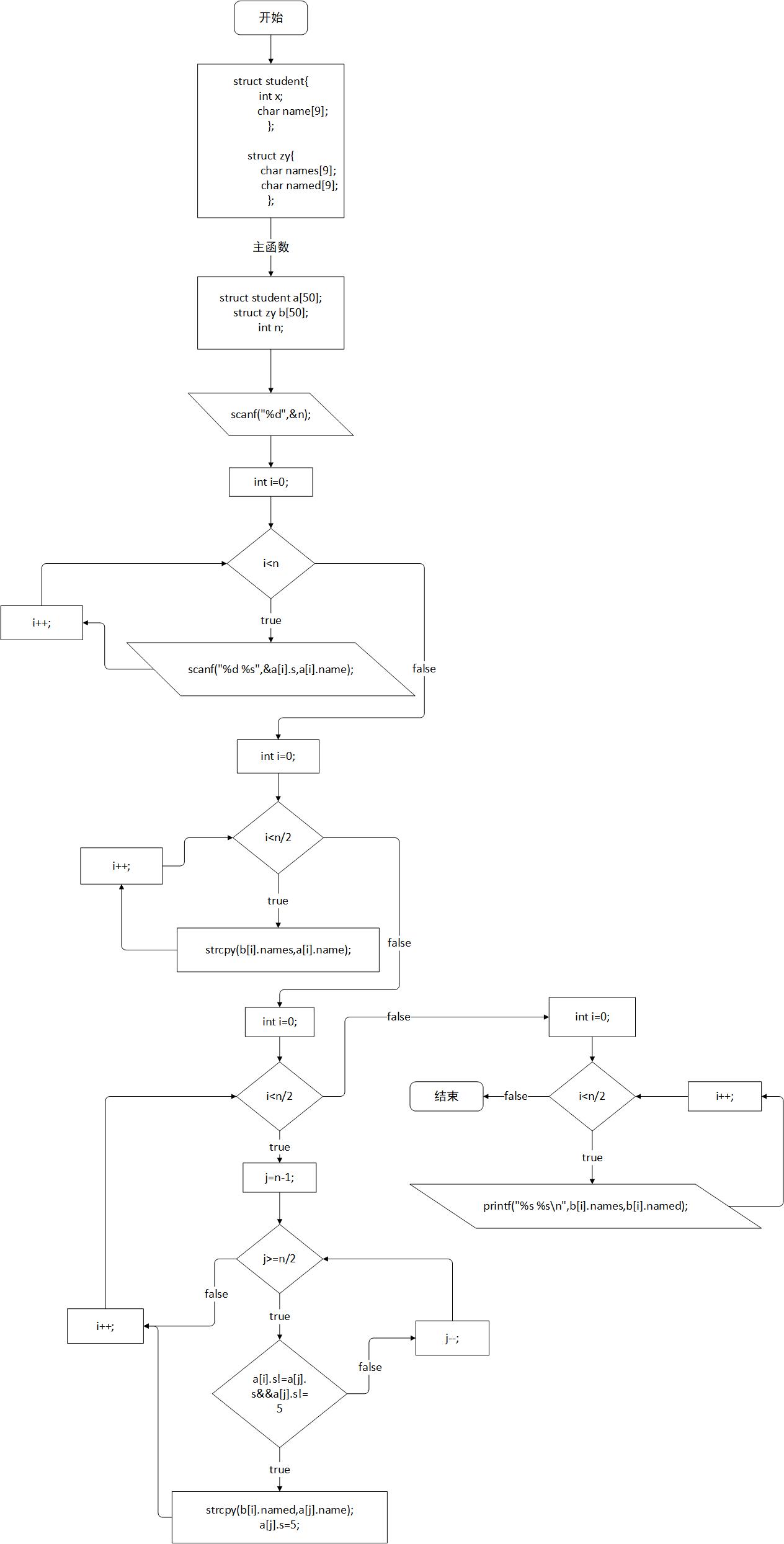 ###3)本题调试过称中遇到的问题及解决办法 这题好难刚开始看题感受好复杂,不知道怎样区分已经匹配的和没匹配的,所以询问了下同伴, ###4)运行截图 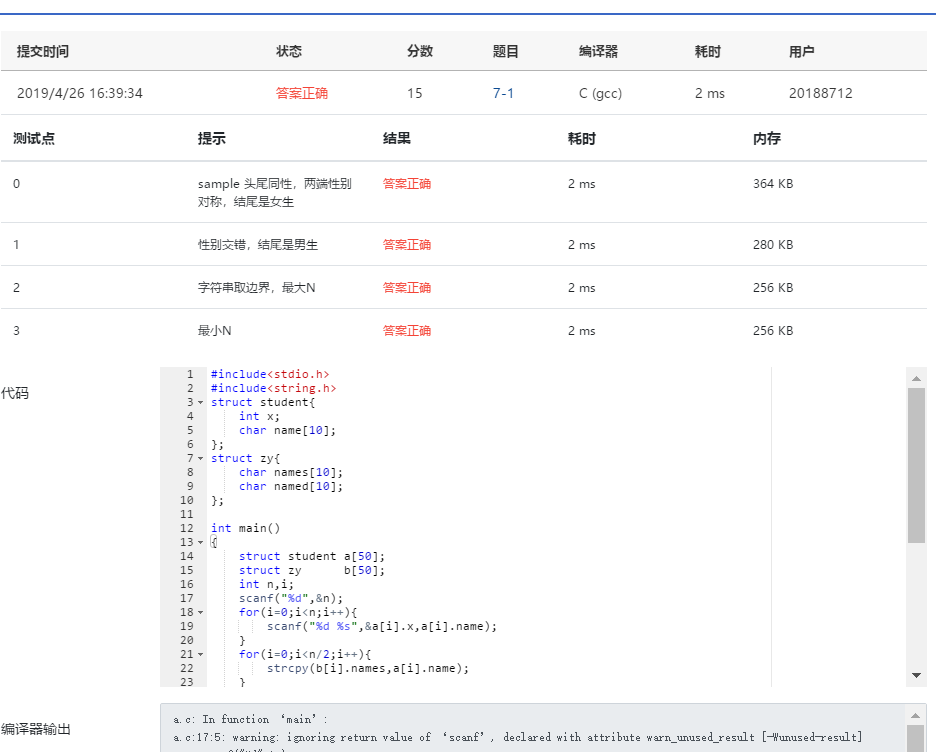 ##7-2 考试座位号 (15 分) 每一个 PAT 考生在参加考试时都会被分配两个座位号,一个是试机座位,一个是考试座位。正常状况下,考生在入场时先获得试机座位号码,入座进入试机状态后,系统会显示该考生的考试座位号码,考试时考生须要换到考试座位就座。但有些考生迟到了,试机已经结束,他们只能拿着领到的试机座位号码求助于你,从后台查出他们的考试座位号码。 输入格式: 输入第一行给出一个正整数 N(≤1000),随后 N 行,每行给出一个考生的信息:准考证号 试机座位号 考试座位号。其中准考证号由 16 位数字组成,座位从 1 到 N 编号。输入保证每一个人的准考证号都不一样,而且任什么时候候都不会把两我的分配到同一个座位上。 考生信息以后,给出一个正整数 M(≤N),随后一行中给出 M 个待查询的试机座位号码,以空格分隔。 输出格式: 对应每一个须要查询的试机座位号码,在一行中输出对应考生的准考证号和考试座位号码,中间用 1 个空格分隔。 输入样例:
4
3310120150912233 2 4
3310120150912119 4 1
3310120150912126 1 3
3310120150912002 3 2
2
3 4指针
输出样例:
3310120150912002 2
3310120150912119 1
###1)实验代码
include<stdio.h>
define MAXN 1000
struct student{
char xh[20];
int a;
int k;
};
int main()
{
struct student b[MAXN];
int n,m,x[MAXN],i;
scanf("%d",&n);
for(int i=0;i<n;i++){
scanf("%s %d %d",b[i].xh,&b[i].a,&b[i].k);
}
scanf("%d",&m);
for(i=0;i<m;i++){
scanf("%d",&x[i]);
}
//查询
for(i=0;i<m;i++){
for(int j=0;j<n;j++){
if(x[i]==b[j].a){
printf("%s %d\n",b[j].xh,b[j].k);
break;
}
}
}
}
2)设计思路

3)本题调试过称中遇到的问题及解决办法
本身忽视了字符串会以‘/0‘结尾所以第一次写的时候定义数组char【16】.
4)运行截图
二.预习题
1.什么是递归函数?
递归函数是有条件终止的死循环函数,能够把它理解成是for循环与死循环的结合的函数。
优势:代码简洁,好理解
缺点:1.递归因为是函数调用自身,而函数调用是有时间和空间的消耗的:每一次函数调用,都须要在内存栈中分配空间以保存参数、返回地址以及临时变量,而往栈中压入数据和弹出数据都须要时间。->效率
2.递归中不少计算都是重复的,因为其本质是把一个问题分解成两个或者多个小问题,多个小问题存在相互重叠的部分,则存在重复计算,如fibonacci斐波那契数列的递归实现。->效率
3.调用栈可能会溢出,其实每一次函数调用会在内存栈中分配空间,而每一个进程的栈的容量是有限的,当调用的层次太多时,就会超出栈的容量,从而致使栈溢出。->性能
3.如何概括出递归式?
(一)代换法:
实质上就是数学概括法,先对一个小的值作假设,而后推测更大的值得正确性。因为是数学概括法,那么咱们就须要对值进行猜想。如今,咱们看下面这个例子:
咱们先假设一个结论T(n) = O(lg(n - b)),而且假设对T(n / 2上取整)成立(这就是数学概括法了),那么把T(n / 2上取整)用假设的结论进行代换,咱们有T(n) <= lg((n - b)) / 2上取整)
<= lg((n - b) / 2 + 1) + 1 = lg(n - b + 2),对于任意的b >= 2,即知足要求T(n) <= lg(n) = O(lgn)。证毕。
这是一个很简单的例子,可是其中有些事情仍是要交代的。
一个是结论的猜想不是一个容易的事情。另外一个是在上面的例子中我没有直接下结论说T(n) = O(lg(n)),而是减去了一个常数b,这是为何呢?答案是:we can prove something stronger for a given value by assuming something stronger for smaller values.还有一点值得说明,请看下面这个例子:
这里出现了sqrt(n),咱们采用变量代换的方法:令n = 2 ^ m,则上式变为T(2 ^ m) = 2T(2 ^ (m / 2) ),再设S(m) = T(2 ^ m),则获得S(m) = 2S(m / 2) + 1。咱们先假设S(m) = m - b <= O(m),且对S(m / 2)成立,那么S(m) = 2 * (m - b) / 2 + 1 = m - b + 1,对于任意的b >= 1都有S(m) = O(m),而后回代有T(n) = T( 2 ^ m) = S(m) = O(m) = O(lgn)。
这里咱们采用了变量代换的方法。若是假设时,感受变量不明朗,那么这是一种颇有效的方法。
(二)递归树方法:
利用递归树方法求算法复杂度我想最好的例子就是归并排序了,这里我不想拿归并排序作例子,而只是用书中一些更简单形象的例子来讲明:
根据上式咱们创建递归式T(n) = 3T(n / 4) + cn^2,这里咱们抛去上下界函数的影响(sloppiness that we can tolerate),而且把Theta(n ^ 2)用cn^2代替。下面创建递归树模型:
在递归树中,每个结点都表明一个子代价,每层的代价是该层全部子代价的总和,总问题的代价就是全部层的代价总和。
因此,咱们利用递归树求解代价,须要知道什么呢,一个是每一层的代价,一个是层数,就是这两个。
这些,都须要咱们用觉察的态度来发现,而事实证实,这不是一件难事,不少状况下是有规律可循的。
咱们且看上面这个例子,递归树的构造很简单,当递归调用到边界是,就达到了常量T(1),达到常量T(1)所用到的递归次数就是整个递归树的深度,咱们从图中能够获得第i层的结点的代价为n / ( 4 ^ i ),当n / (4 ^ i) = 1即i = log4(n)时,递归到达了边界,因此,整个递归树的深度就是i = log4(n)。咱们要求的总的代价是全部的总和,结果为O(n ^ 2)。计算过程我就再也不累述了。可是,递归树并非都是这样的满的树,也就是否是每一层的结点都是相同的结构,因此咱们在构造递归树的时候要仔细看好这一点,才能保证在计算时不会出错。
(三)主方法:
其实应该叫作主定理方法,利用这个方法,咱们只须要记住主定理的三种状况,而且在知足必定的条件下,就能够速度解出递归式。主定理的三种状况不在这里给出,必定条件我只说一下我对于多项式大于(或小于)的理解,好比x和1.1x,那么x就是多项式小于1.1x,两者差了一个多项式(0.1x),而至于x与xlgx就不存在多项式大于(或小于)的关系。
三.预习的主要内容。
1.递归函数基本概念。
四.学习进度条
| 周/日期 | 这周所花的时间 | 代码行 | 学到的知识点简介 | 目前比较迷惑的问题 |
|---|---|---|---|---|
| 2/25-3/3 | 5h | 39 | 一维数组的定义和引用及初始化 | 字符数组和整型数组的区别 |
| 3/4-3/10 | 5h | 47 | 文件的读取、写入, 处理和开关;文件的打开方. | 文件的分类,什么是二进制文件;字符数组的读取和写入 |
| 3/11-3/17 | 6h | 57 | 二维数组的定义及应用 | 二维数组的行和列的嵌套循环输入和输出 |
| 3/18-3/24 | 3h | 33 | 选择排序法、冒泡排序法和二分查找法 | 不清楚选择排序法和冒泡排序法的区别 |
| 3/25-3/31 | 10h | 40 | 字符数组和字符串的区别,字符串的输入输出方式和格式,二维数组更高级的运用。 | 不清楚指针在程序中的做用与使用 |
| 4/1-4/7 | 6h | 50 | 变量、内存单元和地址之间的关系;指针变量的定义及初始化,指针变量的基本运算,指针、数组和地址间的关系 | 冒泡排序法不太明白 |
| 4/8-4/14 | 12h | 99 | 掌握数组名做为函数参数的用法,理解指针、数组和地址之间的关系,理解指针和数组能够实现相同的操做 | 作基础题第二题时发现之前的知识不少都忘记了 |
| 4/15-4/21 | 12h | 132 | 掌握经常使用字符串函数以及使用指针操做字符串的方法,理解动态内存分配 | 各个动态内存分配函数的区别仍是不太清楚 |
| 4/22-4/28 | 12h | 135 | 合理定义结构,使用结构变量与结构数组编程,掌握结构指针的操做,并应用于函数传递 | 解递归式的三种方法不懂 |
五.学习感悟
这周题目的第一题和最后一题还好就是第二题很难,第二题的困难让我发觉了问同窗的重要性和查资料的重要性。
六.结对编程感想
过程:此次我在第二题上遇到了很大的阻碍感谢同伴的帮忙。
感想:结队编程真的对咱们有很大的帮助啊,假若不是同伴帮忙我应该作不出来的。
七.表格和折线图
| 时间 | 代码行数 | 博客字数 |
|---|---|---|
| 第一周 | 39 | 400 |
| 第二周 | 47 | 500 |
| 第三周 | 57 | 550 |
| 第四周 | 98 | 600 |
| 第五周 | 88 | 700 |
| 第六周 | 70 | 800 |
| 第七周 | 99 | 900 |
| 第八周 | 150 | 1500 |
| 第九周 | 120 | 2500 |
|
- 1. 2019春第九周做业
- 2. 2019 第九周做业
- 3. 2019春季第九周做业
- 4. 第九周做业
- 5. linux第九周做业
- 6. [python做业] [第九周]
- 7. 2019春第八周做业
- 8. 2019春第六周做业
- 9. 2019春第四周做业
- 10. 2019 第八周做业
- 更多相关文章...
- • Rust 生命周期 - RUST 教程
- • SVN 生命周期 - SVN 教程
- • 使用Rxjava计算圆周率
- • RxJava操作符(九)Connectable Observable Operators
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 2019春第九周做业
- 2. 2019 第九周做业
- 3. 2019春季第九周做业
- 4. 第九周做业
- 5. linux第九周做业
- 6. [python做业] [第九周]
- 7. 2019春第八周做业
- 8. 2019春第六周做业
- 9. 2019春第四周做业
- 10. 2019 第八周做业