svm支持向量机 学习笔记
1简介
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、 非线性 及 高维模式识别 中表现出许多特有的优点,并可以推广应用到函数拟合等其余机器学习问题中。算法
支持向量机方法是创建在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度,Accuracy)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳折衷,以期得到最好的推广能力(或称泛化能力)。机器学习
概念
- 支持向量:就是支持或支撑平面上把两类类别划分开来的超平面的向量点
- 机:方法
- 监督学习:计算机学习已经建立好的分类系统,SVM最好的监督学习方法(深度学习)
- 非监督学习:没有能够学习的样本
2介绍
用二维的例子解释SVM,能够拓展到n维函数
如何区分线性可分和线性不可分
- 寻找超平面(1,2,3,....n维)
- 超平面全部的变量的偏导数为常数就说这个样本线性可分
2.1线性可分
二维状况下:就是能够用一条或几条直线把属于不一样类别的样本点分开
N维状况下:就是能够用一个超平面(线,面,超平面,n-1维)来分隔两类点学习
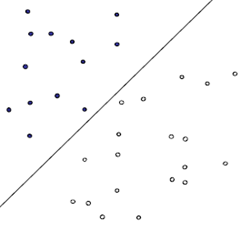
如何找到最优的那条直线?是须要解决的问题优化

方法以下:spa
从直观上来讲,就是分割的间隙越大越好,把两个类别的点分得越开越好。就像咱们平时判断一我的是男仍是女,就是很难出现分错的状况,这就是男、女两个类别之间的间隙很是的大致使的,让咱们能够更准确的进行分类。
在SVM中,称为Maximum Marginal,是SVM的一个理论基础之一
上图被红色和蓝色的线圈出来的点就是所谓的支持向量!.net
上图就是线性方程,能够得出M:
另外支持向量位于wx + b = 1与wx + b = -1的直线上,咱们在前面乘上一个该点所属的类别y(还记得吗?y不是+1就是-1),就能够获得支持向量的表达式为:y(wx + b) = 1,这样就能够更简单的将支持向量表示出来了。code
至此二维已经能求出w和b的值,咱们扩展到n维空间里:
咱们要优化求解的表达式:blog
||w||的意思是w的二范数(空间两个向量的直线距离),这两个式子是等价的,之因此要写成这样是为了后边的求导
这个式子有还有一些限制条件,完整的写下来,应该是这样的:ip
这个实际上是一个带约束的二次规划(quadratic programming, QP)问题,是一个凸问题,凸问题就是指的不会有局部最优解,能够想象一个漏斗,无论咱们开始的时候将一个小球放在漏斗的什么位置,这个小球最终必定能够掉出漏斗,也就是获得全局最优解。s.t.后面的限制条件能够看作是一个凸多面体,咱们要作的就是在这个凸多面体中找到最优解。
转化为对偶问题,优化求解
这个优化问题能够用拉格朗日乘子法去解,使用了KKT条件的理论,这里直接做出这个式子的拉格朗日目标函数:
首先让L关于w,b最小化,分别令L关于w,b的偏导数为0,获得关于原问题的一个表达式:
将两式带回L(w,b,a)获得对偶问题的表达式
新问题加上其限制条件是(对偶问题):
这个就是咱们须要最终优化的式子。至此,获得了线性可分问题的优化式子。
得出这个式子彻底是为了之后的优化计算而来,有不少方法,如SMO(序列最小最优化)等
2.2线性不可分
方法一:用曲线分隔开(核函数)
让空间从本来的线性空间变成一个更高维的空间,在这个高维的线性空间下,再用一个超平面进行划分。
当维度增长到无限维的时候,必定可让任意的两个物体可分了
由于两个不一样的物体确定有不一样的特征
下图是一个典型的线性不可分的状况
事实上,上图所述的这个数据集,是用两个半径不一样的圆圈加上了少许的噪音生成获得的,因此,一个理想的分界应该是一个“圆圈”而不是一条线(超平面)。若是用 X1 和 X2 来表示这个二维平面的两个坐标的话,咱们知道一条二次曲线(圆圈是二次曲线的一种特殊状况)的方程能够写做这样的形式:
注意上面的形式,若是咱们构造另一个五维的空间,其中五个坐标的值分别为 $Z_1=X_1, Z_2=X_1^2, Z_3=X_2, Z_4=X_2^2, Z_5=X_1X_2$,那么显然,上面的方程在新的坐标系下能够写做:
这个列子为了直观比较特殊,不用投射到五维空间,用三维空间便可获得:
$Z_1=X^2_1, Z_2=X_2^2, Z_3=X_2 $
那么在新的空间中原来的数据将变成线性可分的,从而使用以前咱们推导的线性分类算法就能够进行处理了。这正是 Kernel 方法处理非线性问题的基本思想。
核函数
用线性可分状况下优化的公式:
咱们能够将红色这个部分进行改造,令:
这个式子所作的事情就是将线性的空间映射到高维的空间,k(x, xj)有不少种,下面是比较典型的两种:
上面这个核称为多项式核,下面这个核称为高斯核,高斯核甚至是将原始空间映射为无穷维空间,另外核函数有一些比较好的性质,好比说不会比线性条件下增长多少额外的计算量,等等,这里也再也不深刻。通常对于一个问题,不一样的核函数可能会带来不一样的结果,通常是须要尝试来获得的。
经常使用核函数
上面这个核称为多项式核,下面这个核称为高斯核,高斯核甚至是将原始空间映射为无穷维空间,另外核函数有一些比较好的性质,好比说不会比线性条件下增长多少额外的计算量,等等,这里也再也不深刻。通常对于一个问题,不一样的核函数可能会带来不一样的结果,通常是须要尝试来获得的。
还有一个线性核,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”二者在形式上统一块儿来了(意思是说,我们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,而后再代入不一样的核,即可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
核函数本质
上面说了这么一大堆,读者可能仍是没明白核函数究竟是个什么东西?我再简要归纳下,即如下三点:
- 实际中,咱们会常常遇到线性不可分的样例,此时,咱们的经常使用作法是把样例特征映射到高维空间中去(如上文2.2节最开始的那幅图所示,映射到高维空间后,相关特征便被分开了,也就达到了分类的目的);
2.但进一步,若是凡是遇到线性不可分的样例,一概映射到高维空间,那么这个维度大小是会高到可怕的(如上文中19维乃至无穷维的例子)。那咋办呢?
此时,核函数就隆重登场了,核函数的价值在于它虽然也是讲特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表如今了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。
方法二:用直线分隔开(不用去保证可分性)(软间隔)
- 欠拟合
- 过拟合
数据中的一些特殊值是噪声
条件限制公式:
- C是一个由用户去指定的系数,表示对分错的点加入多少的惩罚,当C很大的时候,分错的点就会更少,可是过拟合的状况可能会比较严重,当C很小的时候,分错的点可能会不少,不过可能由此获得的模型也会不太正确,因此如何选择C是有不少学问的,不过在大部分状况下就是经过经验尝试获得的。
- 加入惩罚函数:咱们能够为分错的点加上一点惩罚,对一个分错的点的惩罚函数就是这个点到其正确位置的距离
接下来就是一样的,求解一个拉格朗日对偶问题,获得一个原问题的对偶问题的表达式:
蓝色的部分是与线性可分的对偶问题表达式的不一样之处。在线性不可分状况下获得的对偶问题,不一样的地方就是α的范围从[0, +∞),变为了[0, C],增长的惩罚ε没有为对偶问题增长什么复杂度。
3结构风险
模型与真实值之间的偏差叫作风险
使用分类器在样本数据上的分类的结果与真实结果之间的差值来表示。这个差值叫作经验风险,在骁样本上能够保证没有偏差,可是真实值之间不可能保证
之前的机器学习方法都把经验风险最小化做为努力的目标,但后来发现不少分类函数可以在样本集上轻易达到100%的正确率,在真实分类时却一塌糊涂,即所谓的推广能力差,或泛化能力差
泛化偏差界,由两部分刻画:
- 经验风险,表明了分类器在给定样本上的偏差
- 置信风险,表明了咱们在多大程度上能够信任分类器在未知文本上分类的结果
- 样本数量,显然给定的样本数量越大,咱们的学习结果越有可能正确,此时置信风险越小
- 分类函数的VC维,显然VC维越大,推广能力越差,置信风险会变大
泛化偏差界的公式为:
R(w)≤Remp(w)+Ф(n/h)
公式中R(w)就是真实风险,Remp(w)就是经验风险,Ф(n/h)就是置信风险。
统计学习的目标从经验风险最小化变为了寻求经验风险与置信风险的和最小,即结构风险最小。
SVM正是这样一种努力最小化结构风险的算法。
VC维
定义:对一个指标函数集,若是存在H个样本可以被函数集中的函数按全部可能的2的H次方种形式分开,则称函数集可以把H个样本打散;函数集的VC维就是它能打散的最大样本数目H。
二维:VC维为3
VC维反映了函数集的学习能力,VC维越大则学习机器越复杂(容量越大),遗憾的是,目前尚没有通用的关于任意函数集VC维计算的理论,只对一些特殊的函数集知道其VC维。例如在N维空间中线形分类器和线形实函数的VC维是N+1。(经过2维的推导)
小样本 : 并非说样本的绝对数量少(实际上,对任何算法来讲,更多的样本几乎老是能带来更好的效果),而是说与问题的复杂度比起来,SVM算法要求的样本数是相对比较少的。
是指SVM擅长应付样本数据线性不可分的状况,主要经过松弛变量(也有人叫惩罚变量)和核函数技术来实现,这一部分是SVM的精髓,之后会详细讨论。多说一句,关于文本分类这个问题到底是不是线性可分的,尚没有定论,所以不能简单的认为它是线性可分的而做简化处理,在水落石出以前,只好先当它是线性不可分的(反正线性可分也不过是线性不可分的一种特例而已,咱们向来不怕方法过于通用)。
- 高维模式识别是指样本维数很高,例如文本的向量表示,若是没有通过另外一系列文章(《文本分类入门》)中提到过的降维处理,出现几万维的状况很正常,其余算法基本就没有能力应付了,SVM却能够,主要是由于SVM 产生的分类器很简洁,用到的样本信息不多(仅仅用到那些称之为“支持向量”的样本,此为后话),使得即便样本维数很高,也不会给存储和计算带来大麻烦
- VC维是对函数类的一种度量,能够简单的理解为问题的复杂程度,VC维越高,一个问题就越复杂。
- 1. 支持向量机 SVM-学习笔记
- 2. 支持向量机学习笔记-SVM
- 3. 学习笔记-支持向量机(SVM)
- 4. 机器学习:支持向量机(SVM)
- 5. 机器学习——支持向量机(SVM)
- 6. [机器学习] 支持向量机(SVM)
- 7. 【机器学习】支持向量机(SVM)
- 8. 机器学习:支持向量机(svm)
- 9. 机器学习(支持向量机-SVM)
- 10. 机器学习————SVM支持向量机
- 更多相关文章...
- • R 绘图 - 中文支持 - R 语言教程
- • 您已经学习了 XML Schema,下一步学习什么呢? - XML Schema 教程
- • Tomcat学习笔记(史上最全tomcat学习笔记)
- • 适用于PHP初学者的学习线路和建议
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 升级Gradle后报错Gradle‘s dependency cache may be corrupt (this sometimes occurs
- 2. Smarter, Not Harder
- 3. mac-2019-react-native 本地环境搭建(xcode-11.1和android studio3.5.2中Genymotion2.12.1 和VirtualBox-5.2.34 )
- 4. 查看文件中关键字前后几行的内容
- 5. XXE萌新进阶全攻略
- 6. Installation failed due to: ‘Connection refused: connect‘安卓studio端口占用
- 7. zabbix5.0通过agent监控winserve12
- 8. IT行业UI前景、潜力如何?
- 9. Mac Swig 3.0.12 安装
- 10. Windows上FreeRDP-WebConnect是一个开源HTML5代理,它提供对使用RDP的任何Windows服务器和工作站的Web访问
- 1. 支持向量机 SVM-学习笔记
- 2. 支持向量机学习笔记-SVM
- 3. 学习笔记-支持向量机(SVM)
- 4. 机器学习:支持向量机(SVM)
- 5. 机器学习——支持向量机(SVM)
- 6. [机器学习] 支持向量机(SVM)
- 7. 【机器学习】支持向量机(SVM)
- 8. 机器学习:支持向量机(svm)
- 9. 机器学习(支持向量机-SVM)
- 10. 机器学习————SVM支持向量机