一、前言
| 这个做业属于哪一个课程 | 班级连接 |
| 这个做业要求在哪里 | 做业要求 |
| 这个做业的目标 | 使用github、规范代码 |
| 做业正文 | 做业正文 |
| 其余参考文献 | 暂无 |
二、PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务须要多少时间 | 490 | 470 |
| Development | 开发 | 240 | 210 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 30 |
| Design Spec | 生成设计文档 | 10 | 10 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| Design | 具体设计 | 10 | 10 |
| Coding | 具体编码 | 240 | 210 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 470 | 470 |
| Reporting | 报告 | 10 | 10 |
| Test Repor | 测试报告 | 10 | 10 |
| Size Measurement | 计算工做量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 过后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 890 | 870 |
三、思路描述
<img src="https://img2018.cnblogs.com/blog/1918331/202002/1918331-20200205215926796-2062364536.png" style="width:200px"> ![]()html
四、实现过程
<img src="https://img2018.cnblogs.com/blog/1918331/202002/1918331-20200205222243740-754093877.png" style="width:220px"> ![]()vue
五、代码说明
这里是代码地址,有详细注释
命令行参数与统计结果的数据结构以下:
 代码仅由如下三部分构成,共130余行:node
代码仅由如下三部分构成,共130余行:node
1.得到命令行参数的代码:
if(argv[0]!='list') throw new Error('仅能接受list命令!')
argv.slice(1).forEach(v => {
var checked = false //checked为true,说明该参数是一个以-为前缀的key
for (item of Object.keys(CmdParam))
if (v == '-' + item) {
reading = item
checked = true
break
}
!checked && CmdParam[reading].push(v) //统计键值对
})
if(!fs.existsSync(CmdParam.log[0])) throw new Error('输入的日志目录不存在!')
if (fs.readdirSync(CmdParam.log[0]).sort().reverse()[0].split('.')[0] < CmdParam.date[0])
throw new Error('日期超出范围!(-date不会提供在日志最晚一天后的日期)');
if (!CmdParam.date[0])
return fs.readdirSync(CmdParam.log[0]).sort().reverse()[0].split('.')[0].split('-') //最大日期
else //指定了日期
return CmdParam.date[0].split('-')
2.匹配文件内容的代码:
data = data.split('\n') //分行,data是单个文件内的所有数据
data.forEach((line) => {
var res = []
function match(reg, hasTwoPvovinces) { //匹配正则,清洗数据以及初始化
if (/\/\//.test(line)) return false //若是是注释,忽略掉
var res = reg.exec(line)
if (!res) return
for (key of Object.keys(Total)) { //初始化数据数字为Number类型,防止NaN
if (!Total[key][res[1]]) { //非undefined类型表明已经初始化过
provinces.add(res[1]) //顺便收集惟一省份
Total[key][res[1]] = 0
}
if (hasTwoPvovinces && !Total[key][res[2]]) { //同上,而且判断要收集第三项数据
provinces.add(res[2]) //顺便收集惟一省份
Total[key][res[2]] = 0
}
}
return res.slice(1, 4) //返回正则匹配的组内容
}
if (res = match(/(\S{2,3})\s新增 感染患者 (\d*)人/g)) //正则并收集数据
Total.ip[res[0]] += Number(res[1])
if (res = match(/(\S{2,3})\s新增 疑似患者 (\d*)人/g))
Total.sp[res[0]] += Number(res[1])
if (res = match(/(\S{2,3})\s疑似患者 流入 (\S{2,3})\s(\d*)人/g, true)) {
Total.sp[res[0]] -= Number(res[2])
Total.sp[res[1]] += Number(res[2])
}
if (res = match(/(\S{2,3})\s感染患者 流入 (\S{2,3})\s(\d*)人/g, true)) {
Total.ip[res[0]] -= Number(res[2])
Total.ip[res[1]] += Number(res[2])
}
if (res = match(/(\S{2,3})\s死亡 (\d*)人/g)) {
Total.ip[res[0]] -= Number(res[1])
Total.dead[res[0]] += Number(res[1])
}
if (res = match(/(\S{2,3})\s治愈 (\d*)人/g)) {
Total.cure[res[0]] += Number(res[1])
Total.ip[res[0]] -= Number(res[1])
}
if (res = match(/(\S{2,3})\s疑似患者 确诊感染 (\d*)人/g)) {
Total.ip[res[0]] += Number(res[1])
Total.sp[res[0]] -= Number(res[1])
}
if (res = match(/(\S{2,3})\s排除 疑似患者 (\d*)人/g))
Total.sp[res[0]] -= Number(res[1])
})
3.整理数据并输出的代码:
var provincesSorted = []
for (let item of Provinces.keys()) { //提取集合里的省份
provincesSorted.push(item)
}
provincesSorted = provincesSorted.sort((a, b) => { //进行汉字拼音排序
return prior.indexOf(a) - prior.indexOf(b)
})
for (let item of Object.keys(Total)) { //统计'全国'的数据
let sum = 0
for (let num of Object.values(Total[item]))
sum += num
Total[item]['全国'] = sum
}
provincesSorted.unshift('全国') //确保‘全国’必定在其余省份的前面
if (!CmdParam.type.length) CmdParam.type = ['ip', 'sp', 'cure', 'dead'] // 不指定-type即为输出所有四项
provincesSorted.forEach((v) => {
if (!(CmdParam.province.length == 0 || CmdParam.province.includes(v))) return //筛选-province省份
article += `${v}` //开始处理输出数据的附加项-type
if (CmdParam.type.includes('ip')) article += ` 感染患者${Total.ip[v]}人`
if (CmdParam.type.includes('sp')) article += ` 疑似患者${Total.sp[v]}人`
if (CmdParam.type.includes('cure')) article += ` 治愈${Total.cure[v]}人`
if (CmdParam.type.includes('dead')) article += ` 死亡${Total.dead[v]}人`
article += `\n`
})
article += `// 该文档并不是真实数据,仅供测试使用\n// 命令:node InfectStatistic ${cmd}`
fs.writeFileSync(CmdParam.out[0], article, 'utf-8') //最后写入文件
六、单元测试截图和描述
1.正确性测试
2.日志记录混合
<!--<img src="https://img2018.cnblogs.com/blog/1918331/202002/1918331-20200205232016472-1469081961.png" style="width:500px">-->git
测试结果
<!--<img src="https://img2018.cnblogs.com/blog/1918331/202002/1918331-20200206113916675-940302290.png" style="width:700px">-->es6
3.非法时间测试
最晚日志日期的当天,能够正常输出
最晚日志日期的下一天,抛出错误
4.同时限定省份和类型
5.不提供日期参数,则设置为日志最大日期
6.mocha与chai单元测试框架结果
七、覆盖率优化和性能测试,性能优化截图和描述
尴尬的地方来了, 最强的覆盖率工具Istanbul没法传入命令行额外参数,这就使其永远没法覆盖到占比不小的参数处理部分, 覆盖率也就失去了意义... 折腾了好久也没能找到合适的替代品(也许,几乎没有人会在命令行node里传额外参数吧) 因此我只能,把命令行参数处理部分换掉,以下: 分析:抛出Error错误的行数没法覆盖,小部分二选一的分支没法覆盖。github
<div style="display:flex;"> <img src="https://img2018.cnblogs.com/blog/1918331/202002/1918331-20200205233259638-1567344822.png"> <img src="https://img2018.cnblogs.com/blog/1918331/202002/1918331-20200205235227733-1355919960.png"> </div> 减小代码耦合会使代码更简洁易懂、后期维护成本低,但也会略微损失性能,比方说用迭代器遍历对象的键。 性能优化方面,在采起“正则预编译”、“手动列省份顺序来替换汉字排序localeCompare()”的措施后,耗时明显下降。  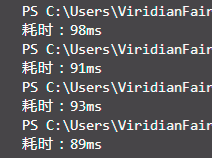 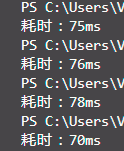 待完善的部分:代码风格的面向对象部分不足;改成异步读写文件会提升效率,但因为处理顺序的限制,理论上讲性能提高颇有限。web
八、git仓库连接、代码规范连接
九、心路历程和收获
最大的感觉就是,因为第一次接触单元测试和覆盖率,来回折腾了好久,尤为是对IDE没有很好支持的人来讲。 (jetbrains全家桶真的太强了...) 因为本身英语很烂,看不少插件和库的教程也是迷迷糊糊,但愿本身能更好提升探索未知技术的能力。 而后是撰写博客和完备的测试,这对初入茅庐的我略有陌生,可是它对养成良好的代码习惯和反思本身大有裨益。 最后是习惯于使用github很是重要,完善的项目管理功能能够帮助咱们专一于代码自己,而没必要花心思在版本迭代、云端备份等鸡零狗碎的东西上。websocket
十、技术路线图相关的5个仓库
新冠肺炎地图:涉及不少地图相关应用,以及不少eCharts特性的实践 vue移动端耦合度更高的demo:基于移动端的vue项目,不过少部分特性已通过时 聊天室:简易的websocket的demo,熟悉websocket-client的相关API 新冠肺炎数据:对丁香园网站的新冠肺炎数据爬取,并用eCharts进行汇总展现 es6全面的教程:但仍是要结合实际,好比generator用的人实在太少了数据结构