细说React(二)
上篇文章主要介绍了React的基本用法,此次将介绍一个React路由组件—react-router。html
在 web 应用开发中,路由系统是不可或缺的一部分。在浏览器当前的 URL 发生变化时,路由系统会作出一些响应,用来保证用户界面与 URL 的同步。随着单页应用时代的到来,为之服务的前端路由系统也相继出现了。有一些独立的第三方路由系统,好比 director,代码库也比较轻量。固然,主流的前端框架也都有本身的路由,好比 Backbone、Ember、Angular、React 等等。那 react-router 相对于其余路由系统又针对 React 作了哪些优化呢?它是如何利用了 React 的 UI 状态机特性呢?又是如何将 JSX 这种声明式的特性用在路由中?前端
一个简单的示例
如今,咱们经过一个简易的博客系统示例来解释刚刚遇到的疑问,它包含了查看文章归档、文章详细、登陆、退出以及权限校验几个功能,该系统的完整代码托管在 JS Bin(注意,文中示例代码使用了与之对应的 ES6 语法),你能够点击连接查看。此外,该实例所有基于最新的 react-router 1.0 进行编写。下面看一下 react-router 的应用实例:react
import React from 'react'; import { render, findDOMNode } from 'react-dom'; import { Router, Route, Link, IndexRoute, Redirect } from 'react-router'; import { createHistory, createHashHistory, useBasename } from 'history'; // 此处用于添加根路径 const history = useBasename(createHashHistory)({ queryKey: '_key', basename: '/blog-app', }); React.render(( <Router history={history}> <Route path="/" component={BlogApp}> <IndexRoute component={SignIn}/> <Route path="signIn" component={SignIn}/> <Route path="signOut" component={SignOut}/> <Redirect from="/archives" to="/archives/posts"/> <Route onEnter={requireAuth} path="archives" component={Archives}> <Route path="posts" components={{ original: Original, reproduce: Reproduce, }}/> </Route> <Route path="article/:id" component={Article}/> <Route path="about" component={About}/> </Route> </Router> ), document.getElementById('example'));
若是你之前并无接触过 react-router,相反只是用过刚才提到的 Backbone 的路由或者是 director,你必定会对这种声明式的写法感到惊讶。不过细想这也是情理之中,毕竟是只服务与 React 类库,引入它的特性也是无可厚非。仔细看一下,你会发现:git
-
Router 与 Route 同样都是 react 组件,它的 history 对象是整个路由系统的核心,它暴漏了不少属性和方法在路由系统中使用;github
-
Route 的 path 属性表示路由组件所对应的路径,能够是绝对或相对路径,相对路径可继承;web
-
Redirect 是一个重定向组件,有 from 和 to 两个属性;算法
-
Route 的 onEnter 钩子将用于在渲染对象的组件前作拦截操做,好比验证权限;express
-
在 Route 中,可使用 component 指定单个组件,或者经过 components 指定多个组件集合;redux
-
param 经过
/:param的方式传递,这种写法与 express 以及 ruby on rails 保持一致,符合 RestFul 规范;后端
下面再看一下若是使用 director 来声明这个路由系统会是怎样一番景象呢:
import React from 'react'; import { render } from 'react-dom'; import { Router } from 'director'; const App = React.createClass({ getInitialState() { return { app: null } }, componentDidMount() { const router = Router({ '/signIn': { on() { this.setState({ app: (<BlogApp><SignIn/></BlogApp>) }) }, }, '/signOut': { 结构与 signIn 相似 }, '/archives': { '/posts': { on() { this.setState({ app: (<BlogApp><Archives original={Original} reproduct={Reproduct}/></BlogApp>) }) }, }, }, '/article': { '/:id': { on (id) { this.setState({ app: (<BlogApp><Article id={id}/></BlogApp>) }) }, }, }, }); }, render() { return <div>{React.cloneElement(this.state.app)}</div>; }, }) render(<App/>, document.getElementById('example'));
从代码的优雅程度、可读性以及维护性上看绝对 react-router 在这里更胜一筹。分析上面的代码,每一个路由的渲染逻辑都相对独立的,这样就须要写不少重复的代码,这里虽然能够借助 React 的 setState 来统一管理路由返回的组件,将 render 方法作必定的封装,但结果倒是要多维护一个 state,在 react-router 中这一步根本不须要。此外,这种命令式的写法与 React 代码放在一块儿也是略显突兀。而 react-router 中的声明式写法在组件继承上确实很清晰易懂,并且更加符合 React 的风格。包括这里的默认路由、重定向等等都使用了这种声明式。相信读到这里你已经放弃了在 React 中使用 react-router 外的路由系统!
接下来,仍是回到 react-router 示例中,看一下路由组件内部的代码:
const SignIn = React.createClass({ handleSubmit(e) { e.preventDefault(); const email = findDOMNode(this.refs.name).value; const pass = findDOMNode(this.refs.pass).value; // 此处经过修改 localStorage 模拟了登陆效果 if (pass !== 'password') { return; } localStorage.setItem('login', 'true'); const location = this.props.location; if (location.state && location.state.nextPathname) { this.props.history.replaceState(null, location.state.nextPathname); } else { // 这里使用 replaceState 方法作了跳转,但在浏览器历史中不会多一条记录,由于是替换了当前的记录 this.props.history.replaceState(null, '/about'); } }, render() { if (hasLogin()) { return <p>你已经登陆系统!<Link to="/signOut">点此退出</Link></p>; } return ( <form onSubmit={this.handleSubmit}> <label><input ref="name"/></label><br/> <label><input ref="pass"/></label> (password)<br/> <button type="submit">登陆</button> </form> ); } }); const SignOut = React.createClass({ componentDidMount() { localStorage.setItem('login', 'false'); }, render() { return <p>已经退出!</p>; } })
上面的代码表示了博客系统的登陆以及退出功能。登陆成功,默认跳转到 /about 路径下,若是在 state 对象中存储了 nextPathname,则跳转到该路径下。在这里须要指出每个路由(Route)中声明的组件(好比 SignIn)在渲染以前都会被传入一些 props,具体是在源码中的 RoutingContext.js 中完成,主要包括:
-
history 对象,它提供了不少有用的方法能够在路由系统中使用,好比刚刚用到的
history.replaceState,用于替换当前的 URL,而且会将被替换的 URL 在浏览器历史中删除。函数的第一个参数是 state 对象,第二个是路径; -
location 对象,它能够简单的认为是 URL 的对象形式表示,这里要提的是
location.state,这里 state 的含义与 HTML5 history.pushState API 中的 state 对象同样。每一个 URL 都会对应一个 state 对象,你能够在对象里存储数据,但这个数据却不会出如今 URL 中。实际上,数据被存在了 sessionStorage 中;
事实上,刚才提到的两个对象同时存在于路由组件的 context 中,你还能够经过 React 的 context API 在组件的子级组件中获取到这两个对象。好比在 SignIn 组件的内部又包含了一个 SignInChild 组件,你就能够在组件内部经过 this.context.history 获取到 history 对象,进而调用它的 API 进行跳转等操做。
接下来,咱们一块儿看一下 Archives 组件内部的代码:
const Archives = React.createClass({ render() { return ( <div> 原创:<br/> {this.props.original} 转载:<br/> {this.props.reproduce} </div> ); } }); const Original = React.createClass({ render() { return ( <div className="archives"> <ul> {blogData.slice(0, 4).map((item, index) => { return ( <li key={index}> <Link to={`/article/${index}`} query={{type: 'Original'}} state={{title: item.title}}> {item.title} </Link> </li> ) })} </ul> </div> ); } }); const Reproduce = React.createClass({ // 与 Original 相似 })
上述代码展现了文章归档以及原创和转载列表。如今回顾一下路由声明部分的代码:
<Redirect from="/archives" to="/archives/posts"/>
<Route onEnter={requireAuth} path="archives" component={Archives}>
<Route path="posts" components={{
original: Original,
reproduce: Reproduce,
}}/>
</Route>
function requireAuth(nextState, replaceState) {
if (!hasLogin()) {
replaceState({ nextPathname: nextState.location.pathname }, '/signIn');
}
}
上述的代码中有三点值得注意:
-
用到了一个 Redirect 组件,将
/archives重定向到/archives/posts下; -
onEnter 钩子中用于判断用户是否登陆,若是未登陆则使用
replaceState方法重定向,该方法的做用与<Redirect/>组件相似,不会在浏览器中留下重定向前的历史; -
若是使用 components 声明路由所对应的多个组件,在组件内部能够经过
this.props.original(本例中)来获取组件;
到这里,咱们的博客路由系统基本已经讲完了,但愿你可以对 react-router 最基本的 API 及其内部的基本原理有必定的了解。再总结一下 react-router 做为 React 路由系统的特色和优点所在:
-
结合 JSX 采用声明式的语法,很优雅的实现了路由嵌套以及路由回调组件的声明,包括重定向组件,默认路由等,这归功于其内部的匹配算法,能够经过 URL(准确的说应该是 location 对象) 在组件树中准确匹配出须要渲染的组件。这一点绝对完胜 director 等路由在 React 中的表现;
-
不须要单独维护 state 表示当前路由,这一点也是使用 director 等路由免不了要作的;
-
除了路由组件外,还能够经过 history 对象中的
pushState或replaceState方法进行路由和重定向,好比在 flux 的 store 中想要作一个跳转操做就能够经过该方法完成;// 近似于 <Link to={path} state={null}/> history.pushState(null, path); // 近似于 <Redirect from={currentPath} to={nextPath}/> history.replaceState(null, nextPath);
固然还有一些其余的特性没有在这里介绍,好比在大型应用中按需载入路由组件、服务端渲染以及整合 redux/relay 框架,这些都是用其余路由系统很难完成的。接下来的部分主要来说解示例背后的基本原理。
原理分析
在这一部分主要会讲解路由的基本原理,react-router 的状态机特性,在用户点击了 Link 组件后路由系统中到底发生了哪些,前端路由如何处理浏览器的前进和后退功能。
路由的基本原理
不管是传统的后端 MVC 主导的应用,仍是在当下最流行的单页面应用中,路由的职责都很重要,但原理并不复杂,即保证视图和 URL 的同步,而视图能够当作是资源的一种表现。当用户在页面中进行操做时,应用会在若干个交互状态中切换,路由则能够记录下某些重要的状态,好比在一个博客系统中用户是否登陆、在访问哪一篇文章、位于文章归档列表的第几页。而这些变化一样会被记录在浏览器的历史中,用户能够经过浏览器的前进、后退按钮切换状态,一样能够将 URL 分享给好友。简而言之,用户能够经过手动输入或者与页面进行交互来改变 URL,而后经过同步或者异步的方式向服务端发送请求获取资源(固然,资源也可能存在于本地),成功后从新绘制 UI,原理以下图所示:

react-router 的状态机特性
咱们看到 react-router 中的不少特性都与 React 保持了一致,好比它的声明式组件、组件嵌套,固然也包括 React 的状态机特性,由于毕竟它就是基于 React 构建而且为之所用的。回想一下在 React 中,咱们把组件比做是一个函数,state/props 做为函数的参数,当它们发生变化时会触发函数执行,进而帮助咱们从新绘制 UI。那么在 react-router 中将会是什么样子呢?在 react-router 中,咱们能够把 Router 组件当作是一个函数,Location 做为参数,返回的结果一样是 UI,两者的对好比下图所示:
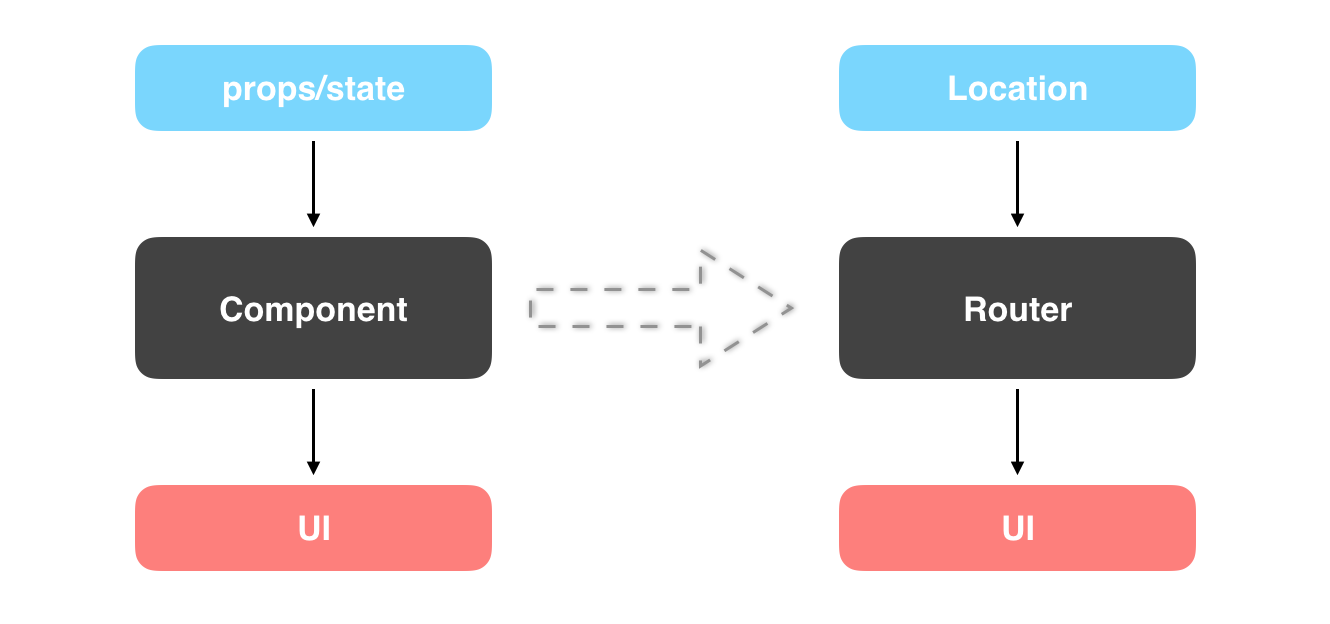
上图说明了只要 URL 一致,那么返回的 UI 界面老是相同的。或许你还很好奇在这个简单的状态机后面到底是什么样子呢?在点击 Link 后路由系统发生了什么?在点击浏览器的前进和后退按钮后路由系统又作了哪些?那么请看下图:

接下来的两部分会对上图作详细的讲解。
点击 Link 后路由系统发生了什么?
Link 组件最终会渲染为 HTML 标签 <a>,它的 to、query、hash 属性会被组合在一块儿并渲染为 href 属性。虽然 Link 被渲染为超连接,但在内部实现上使用脚本拦截了浏览器的默认行为,而后调用了 history.pushState 方法(注意,文中出现的 history 指的是经过 history 包里面的 create*History 方法建立的对象,window.history 则指定浏览器原生的 history 对象,因为有些 API 相同,不要弄混)。history 包中底层的 pushState 方法支持传入两个参数 state 和 path,在函数体内有将这两个参数传输到 createLocation 方法中,返回 location 的结构以下:
location = { pathname, // 当前路径,即 Link 中的 to 属性 search, // search hash, // hash state, // state 对象 action, // location 类型,在点击 Link 时为 PUSH,浏览器前进后退时为 POP,调用 replaceState 方法时为 REPLACE key, // 用于操做 sessionStorage 存取 state 对象 };
系统会将上述 location 对象做为参数传入到 TransitionTo 方法中,而后调用 window.location.hash 或者window.history.pushState() 修改了应用的 URL,这取决于你建立 history 对象的方式。同时会触发 history.listen 中注册的事件监听器。
接下来请看路由系统内部是如何修改 UI 的。在获得了新的 location 对象后,系统内部的 matchRoutes 方法会匹配出 Route 组件树中与当前 location 对象匹配的一个子集,而且获得了 nextState,具体的匹配算法不在这里讲解,感兴趣的同窗能够点击查看,state 的结构以下:
nextState = { location, // 当前的 location 对象 routes, // 与 location 对象匹配的 Route 树的子集,是一个数组 params, // 传入的 param,即 URL 中的参数 components, // routes 中每一个元素对应的组件,一样是数组 };
在 Router 组件的 componentWillMount 生命周期方法中调用了 history.listen(listener) 方法。listener 会在上述 matchRoutes 方法执行成功后执行 listener(nextState),nextState 对象每一个属性的具体含义已经在上述代码中注释,接下来执行 this.setState(nextState) 就能够实现从新渲染 Router 组件。举个简单的例子,当 URL(准确的说应该是 location.pathname) 为 /archives/posts 时,应用的匹配结果以下图所示:

对应的渲染结果以下:
<BlogApp>
<Archives original={Original} reproduce={Reproduce}/>
</BlogApp>
到这里,系统已经完成了当用户点击一个由 Link 组件渲染出的超连接到页面刷新的全过程。
点击浏览器的前进和后退按钮发生了什么?
能够简单地把 web 浏览器的历史记录比作成一个仅有入栈操做的栈,当用户浏览器到某一个页面时将该文档存入到栈中,点击「后退」或「前进」按钮时移动指针到 history 栈中对应的某一个文档。在传统的浏览器中,文档都是从服务端请求过来的。不过现代的浏览器通常都会支持两种方式用于动态的生成并载入页面。
location.hash 与 hashchange 事件
这也是比较简单而且兼容性也比较好的一种方式,详细请看下面几点:
-
使用
hashchange事件来监听window.location.hash的变化 -
hash 发生变化浏览器会更新 URL,而且在 history 栈中产生一条记录
-
路由系统会将全部的路由信息都保存到
location.hash中 -
在 react-router 内部注册了
window.addEventListener('hashchange', listener, false)事件监听器 -
listener 内部能够经过 hash fragment 获取到当前 URL 对应的 location 对象
-
接下来的过程与点击 <Link/> 时保持一致
固然,你会想到不只仅在前进和后退会触发 hashchange 事件,应该说每次路由操做都会有 hash 的变化。确实如此,为了解决这个问题,路由系统内部经过判断 currentLocation 与 nextLocation 是否相等来处理该问题。不过,从它的实现原理上来看,因为路由操做 hash 发生变化而重复调用 transitonTo(location) 这一步确实无可避免,这也是我在上图中所画的虚线的含义。
这种方法会在浏览器的 URL 中添加一个 # 号,不过出于兼容性的考虑(ie8+),路由系统内部将这种方式(对应 history 包中的createHashHistory 方法)做为建立 history 对象的默认方法。
history.pushState 与 popstate 事件
新的 HTML5 规范中还提出了一个相对复杂但更加健壮的方式来解决该问题,请看下面几点:
-
上文中提到了能够经过
window.history.pushState(state, title, path)方法(更多关于 history 对象的详细 API 能够查看这里)来改变浏览器的 URL,实际上该方法同时在 history 栈中存入了 state 对象。 -
在浏览器前进和后退时触发
popstate事件,而后注册window.addEventListener('popstate', listener, false),而且能够在事件对象中取出对应的 state 对象 -
state 对象能够存储一些恢复该页面所须要的简单信息,上文中已经提到 state 会做为属性存储在 location 对象中,这样你就能够在组件中经过
location.state来获取到 -
在 react-router 内部将该对象存储到了 sessionStorage 中,也就是上图中的 saveState 操做
-
接下来的操做与第一种方式一致
使用这种方式(对应 history 包中的 createHistory 方法)进行路由须要服务端要作一个路由的配置将全部请求重定向到入口文件位置,你能够参考这个示例,不然在用户刷新页面时会报 404 错误。
实际上,上面提到的 state 对象不只仅在第二种路由方式中可使用。react-router 内部作了 polyfill,统一了 API。在使用第一种方式建立路由时你会发现 URL 中多了一个相似 _key=s1gvrm 的 query,这个 _key 就是为 react-router 内部在 sessionStorage 中读取 state 对象所提供的。
react-router 相关资源
- 1. 细说React(一)
- 2. 细说react-native中的SectionList
- 3. JMeter(二)详细说明
- 4. 说说React框架
- 5. 二. 细说小程序登录
- 6. 细说shiro之二:组件架构
- 7. rsync(二):inotify+rsync详细说明
- 8. 细说JVM(类文件结构(二))
- 9. Backbone.js学习笔记(二)细说MVC
- 10. 细说中间人攻击(二)
- 更多相关文章...
- • Eclipse 窗口说明 - Eclipse 教程
- • PHP EOF(heredoc) 使用说明 - PHP教程
- • RxJava操作符(二)Transforming Observables
- • Kotlin学习(二)基本类型
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. 细说React(一)
- 2. 细说react-native中的SectionList
- 3. JMeter(二)详细说明
- 4. 说说React框架
- 5. 二. 细说小程序登录
- 6. 细说shiro之二:组件架构
- 7. rsync(二):inotify+rsync详细说明
- 8. 细说JVM(类文件结构(二))
- 9. Backbone.js学习笔记(二)细说MVC
- 10. 细说中间人攻击(二)