浅析Java异常处理机制
关于异常处理的文章已有至关的篇幅,本文简单总结了Java的异常处理机制,并结合代码分析了一些异常处理的最佳实践,对异常的性能开销进行了简单分析。
博客另外一篇文章《[译]Java异常处理的最佳实践》也是关于异常处理的一篇不错的文章。html
请思考: 对比 Exception 和 Error ,两者有何区别? 另外,运行时异常和通常异常有什么区别?java
Exception 和 Error 的区别
首先,要明确的是 Exception 和 Error 都继承自 Throwable 类,Java中只有 Throwable 类型的实例才能够被抛出 (throws) 或 捕获 (catch) ,它是异常处理机制的基本组成类型。sql
Exception 是程序正常运行中,能够预料的意外状况,应该被捕获并进行相应处理。Error 是指在正常状况下,不太可能出现的状况,绝大多数的 Error 都会致使程序(好比 JVM 自身)处于非正常的、不可恢复状态。既然是非正常状况,因此不便于也不须要捕获,常见的如 OutOfMemoryError等,都是 Error 的子类。api
Exception 又分为检查型 (checked) 和 非检查型 (unchecked) 异常,检查型异常必须在源代码里显式的进行捕获处理,这是编译期检查的一部分。数组
非检查型异常(unchecked exception) 就是所谓的运行时异常,如 NullPointerException 和 ArrayIndexOutOfBoundsException 等,一般是能够编码避免的逻辑错误,具体根据须要来判断是否须要捕获,并不会在编译期强制要求。安全
Throwable、Exception、Error 的设计和分类
内置异常类
下图展现了Java中异常类继承关系 oracle
oracle
java.lang 中定义了一些异常类,这里只列举其中常见的一部分,详细查阅 java.lang.Error、java.lang.Exceptionapp
-
Error:分布式
-
LinkageError:ide
-
VirtualMachineError:虚拟机错误。用于指示虚拟机被破坏或者继续执行操做所需的资源不足的状况。
- OutOfMemoryError: 内存溢出错误
- StackOverflowError:栈溢出错误
-
-
Exception
-
检查型异常 (checked exception)
- IOException
- ClassNotFoundException
- InstantiationException
- SQLException
-
非检查型异常 (unchecked exception)
-
RuntimeException
- NullPointerException
- ClassCastException
- SecurityException
- ArithmeticException
- IndexOutOfBoundsException
-
-
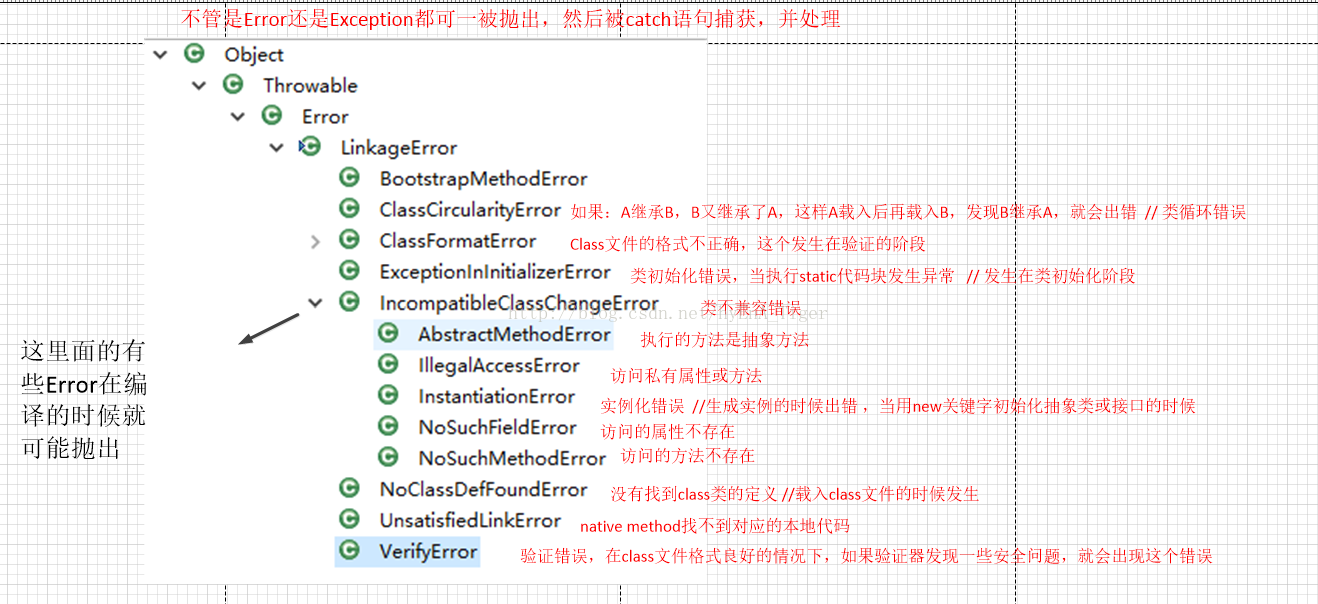
还有一个经典的题目: NoClassDefFoundError 和 ClassNotFoundException 有什么区别?
异常方法
下面是 Throwable 类的主要方法:(java.lang.Throwable)
-
public String getMessage():返回关于发生的异常的详细信息 -
public Throwable getCause():返回一个Throwable 对象表明异常缘由 -
public void printStackTrace():打印toString()结果和栈层次到System.err,即错误输出流。 -
public String toString():Returns a short description of this throwable.
捕获、抛出异常
try-catch-finally
使用try 和 catch 关键字能够捕获异常。
能够在 try 语句后面添加任意数量的 catch 块来捕获不一样的异常。若是保护代码中发生异常,异常被抛给第一个 catch 块,若是匹配,它在这里就会被捕获。若是不匹配,它会被传递给第二个 catch 块。如此,直到异常被捕获或者经过全部的 catch 块。
不管是否发生异常,finally 代码块中的代码总会被执行。在 finally 代码块中,能够作一些资源回收工做,如关闭JDBC链接。
try{
// code
}catch( 异常类型1 ex ){
//..
}catch( 异常类型2 ex){
//..
}catch( 异常类型3 ex ){
//..
}finally{
//..
}
throw、throws
throw 的做用是抛出一个异常,不管它是新实例化的仍是刚捕获到的。throws 是方法可能抛出异常的声明。使用 throws 关键字声明的方法表示此方法不处理异常,而交给方法调用处进行处理,一个方法能够声明抛出多个异常。
例如,下面的方法声明抛出 RemoteException 和 InsufficientFundsException:
public class className
{
public void withdraw(double amount) throws RemoteException,
InsufficientFundsException
{
// Method implementation
if(..)
throw new RemoteException();
else
throw new InsufficientFundsException();
}
//Remainder of class definition
}
try-with-resources 和 multiple catch
从Java 7开始提供了两个有用的特性:try-with-resources 和 multiple catch。try-with-resources 将 try-catch-finally 简化为 try-catch,这实际上是一种语法糖,在编译时会转化为 try-catch-finally 语句。自动按照约定俗成 close 那些扩展了 AutoCloseable 或者 Closeable 的对象,从而替代了finally中关闭资源的功能。如下代码用try-with-resources 自动关闭 java.sql.Statement:
public static void viewTable(Connection con) throws SQLException {
String query = "select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEES";
try (Statement stmt = con.createStatement()) { // Try-with-resources
ResultSet rs = stmt.executeQuery(query);
while (rs.next()) {
String coffeeName = rs.getString("COF_NAME");
int supplierID = rs.getInt("SUP_ID");
float price = rs.getFloat("PRICE");
int sales = rs.getInt("SALES");
int total = rs.getInt("TOTAL");
System.out.println(coffeeName + ", " + supplierID + ", " +
price + ", " + sales + ", " + total);
}
} catch (SQLException e) {
JDBCTutorialUtilities.printSQLException(e);
}
}
值得注意的是,异常抛出机制发生了变化。在过去的 try-catch-finally 结构中,若是 try 块没有发生异常时,直接执行finally块。若是try 块发生异常,catch 块捕捉,而后执行 finally 块。
可是在 try-with-resources 结构中,不论 try 中是否有异常,都会首先自动执行 close 方法,而后才判断是否进入 catch块。分两种状况讨论:
-
try没有发生异常,自动调用close方法,若是发生异常,catch 块捕捉并处理异常。 -
try发生异常,而后自动调用close方法,若是close也发生异常,catch块只会捕捉try块抛出的异常,close方法的异常会在catch中被压制,可是你能够在catch块中,用Throwable.getSuppressed方法来获取到压制异常的数组。
再来看看multiple catch ,当咱们须要同时捕获多个异常,可是对这些异常处理的代码是相同的。好比:
try {
execute(); //exception might be thrown
} catch (IOException ex) {
LOGGER.error(ex);
throw new SpecialException();
} catch (SQLException ex) {
LOGGER.error(ex);
throw new SpecialException();
}
使用 multiple catch 能够把代码写成下面这样:
try {
execute(); //exception might be thrown
} catch (IOException | SQLExceptionex ex) {// Multiple catch
LOGGER.log(ex);
throw new SpecialException();
}
这里须要注意的是,上面代码中 ex是隐式的 final 不能够在catch 块中改变ex。
自定义异常
有的时候,咱们会根据须要自定义异常。自定义的全部异常都必须是 Throwable 的子类,若是是检查型异常,则继承 Exception 类。若是自定义的是运行时异常,则继承 RuntimeException。这个时候除了保证提供足够的信息,还有两点须要考虑:
- 是否须要定义成 Checked Exception,这种类型设计的初衷是为了从异常状况恢复。
- 在保证诊断信息足够的同时,也要考虑避免包含敏感信息,由于那样可能致使潜在的安全问题。例如
java.net.ConnectException的出错信息是"Connection refused(Connection refused)",而不包含具体的机器名、IP、端口等,一个重要考量就是信息安全。相似的状况在日志中也有,好比,用户数据通常是不能够输出到日志里面的。
异常处理的最佳实践
看下面代码,有哪些不当之处?
try {
// …
Thread.sleep(1000L);
} catch (Exception e) {
}
以上代码虽短,但已经违反了异常处理的两个基本原则。
第一,尽可能不要捕获顶层的Exception,而是应该捕获特定异常。 在这里是 Thread.sleep() 抛出的 InterruptedException。咱们但愿本身的代码在出现异常时可以尽可能给出详细的异常信息,而Exception偏偏隐藏了咱们的目的,另外咱们也要保证程序不会捕获到咱们不但愿捕获的异常,而上边的代码将捕获全部的异常,包括 unchecked exception ,好比,你可能更但愿RuntimeException 被扩散出来,而不是被捕获。进一步讲,尽可能不要捕获 Throwable 或者 Error,这样很难保证咱们可以正确处理程序 OutOfMemoryError。
第二,不要生吞(swallow)异常 ,这是异常处理中要特别注意的事情,由于极可能会致使很是难以诊断的诡异状况。当try块发生 checked exception 时,咱们应当采起一些补救措施。若是 checked exception 没有任何意义,能够将其转化为 unchecked exception 再从新抛出。千万不要用一个空的 catch 块捕获来忽略它,程序可能在后续代码以不可控的方式结束,没有人可以轻易判断到底是哪里抛出了异常,以及是什么缘由产生了异常。
try {
// …
} catch (IOException e) {
e.printStackTrace();
}
这段在实验中没问题的代码一般在产品代码中不容许这样处理。
查看printStackTrace()文档开头就是“Prints this throwable and its backtrace to the standard error stream”,问题就在这,在稍微复杂一点的生产系统中,标准出错(STERR)不是个合适的输出选项,由于很难判断出到底输出到哪里去了。尤为是对于分布式系统,若是发生异常,可是没法找到堆栈轨迹(stacktrace),这纯属是为诊断设置障碍。因此,最好使用产品日志,详细地输出到日志系统里。
Throw early, catch late 原则
This is probably the most famous principle about Exception handling. It basically says that you should throw an exception as soon as you can, and catch it late as much as possible. You should wait until you have all the information to handle it properly.
This principle implicitly says that you will be more likely to throw it in the low-level methods, where you will be checking if single values are null or not appropriate. And you will be making the exception climb the stack trace for quite several levels until you reach a sufficient level of abstraction to be able to handle the problem.
看下面的代码段:
public void readPreferences(String fileName){
//...perform operations...
InputStream in = new FileInputStream(fileName);
//...read the preferences file...
}
上段代码中若是 fileName 为 null,那么程序就会抛出 NullPointerException,可是因为没有第一时间暴露出问题,堆栈信息可能很是使人费解,每每须要相对复杂的定位。在发现问题的时候,第一时间抛出,可以更加清晰地反映问题。
修改一下上面的代码,让问题 “throw early”,对应的异常信息就很是直观了。
public void readPreferences(String filename) {
Objects. requireNonNull(filename); // throw NullPointerException
//...perform other operations...
InputStream in = new FileInputStream(filename);
//...read the preferences file...
}
上面这段代码使用了Objects.requireNonNull()方法,下面是它在java.util.Objects里的具体实现:
public static <T> T requireNonNull(T obj) {
if (obj == null)
throw new NullPointerException();
return obj;
}
至于 catch late,捕获异常后,须要怎么处理呢?最差的处理方式,就是的“生吞异常”,本质上实际上是掩盖问题。若是实在不知道如何处理,能够选择保留原有异常的 cause 信息,直接再抛出或者构建新的异常抛出去。在更高层面,由于有了清晰的(业务)逻辑,每每会更清楚合适的处理方式是什么。
异常处理机制的性能开销
从性能角度审视一下Java的异常处理机制,有两个可能会相对昂贵的地方:
-
try-catch代码段会产生额外的性能开销,换个角度说,它每每会影响JVM对代码进行优化,因此建议仅捕获有必要的代码段,尽可能不要一个大的try包住整段的代码;更不要利用异常控制代码流程,这远比咱们一般意义上的条件语句(if/else、switch)要低效。 - Java 每实例化一个 Exception,都会对当时的栈进行快照,这是一个相对比较重的操做。若是发生的很是频繁,这个开销可就不能被忽略了。
因此,对于部分追求极致性能的底层类库,有种方式是尝试建立不进行栈快照的Exception。另外,当咱们的服务出现反应变慢、吞吐量降低的时候,检查发生最频繁的 Exception 也是一种思路。
参考文章:
- Java 异常处理 - runoob.com
- Designing with exceptions :Guidelines and tips on when and how to use exceptions
- Exception和Error有什么区别? - Java核心技术36讲
- 1. java异常处理机制 java异常处理机制
- 2. 异常处理机制分析(Java)
- 3. Java异常处理机制
- 4. java异常处理机制
- 5. Java异常机制处理
- 6. Java 异常处理机制
- 7. JAVA异常处理机制
- 8. Java: 异常处理机制
- 更多相关文章...
- • C# 异常处理 - C#教程
- • PHP 异常处理 - PHP教程
- • 漫谈MySQL的锁机制
- • ☆技术问答集锦(13)Java Instrument原理
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. java异常处理机制 java异常处理机制
- 2. 异常处理机制分析(Java)
- 3. Java异常处理机制
- 4. java异常处理机制
- 5. Java异常机制处理
- 6. Java 异常处理机制
- 7. JAVA异常处理机制
- 8. Java: 异常处理机制