JavaScript:V8编译过程
众所周知ECMAScript语言类型分为:Undefined,Null,Boolean,String,Symbol,Number,和Object。咱们常说前六种数据类型为基础类型,Object为引用类型或者说复杂类型数据。那么咱们有想过为何说Undefined,Null,Boolean,String,Symbol,Number为基础类型,而Object为引用类型?在没有本身看ECMAScript规范以前我没有认真思考过这个问题,你们都这么说,并且不少书上也是这么写的,就这么认定了。javascript
在ECMAScript规范中并无指出Undefined,Null,Boolean,String,Symbol,Number为基础类型,Object为引用类型。咱们来看看规范怎么讲的:前端
4.3.2primitive valuejava
member of one of the types Undefined, Null, Boolean, Number, Symbol, or String as defined in clause 6 NOTEA primitive value is a datum that is represented directly at the lowest level of the language implementation.git
在规范的第六章定义的Undefined, Null, Boolean, Number, Symbol, 和String是原始值,原始值直接表明语言实现的最底层的数据。github
4.3.3object编程
member of the type Object An object is a collection of properties and has a single prototype object. The prototype may be the null value.数组
对象是属性的集合,并有一个原型对象。原型能够为空值。浏览器
规范中并无区分基础数据类型和引用数据类型,那么为何在JavaScript中会有这两个概念呢?这与JavaScript引擎内存管理有关,下面咱们就来聊聊JavaScript引擎编译原理。ruby
语言类型
计算机不能直接理解任何除机器语言之外的语言,咱们一般写的代码是高级语言,计算机不能直接理解,因此必需要将写的高级语言代码翻译成机器语言,计算机才能执行程序。性能优化
目前编程语言主要分为编译型语言和解释型语言,编译型语言是在代码运行前编译器将编程语言转换成机器语言,运行时不须要从新翻译,直接使用编译的结果就好了。而解释型语言也是须要将编程语言转换成机器语言,可是是在运行时转换的。很明显解释型语言的执行速度是慢于编译型语言,解释型语言每次执行都须要把源码转换一次才能执行。
C、C++就是属于编译型语言,编辑源代码、编译和运行是所有分离的,互相是一个职责链的形势。咱们写完源码后,通过编译连接、最后获得本地二进制代码,而后交给操做系统。

ruby、JavaScript等就是属于典型的解释型语言,也是脚本语言,脚本不须要进行编译,而是在运行过程当中直接被解释器解释同时调用操做系统资源运行。对于JavaScript而言,解释器就是JavaScript引擎,早期的JavaScript引擎,也是采用这样的方式编译JavaScript代码的,可是早期V8引擎就不是这种的编译过程了,下面会讲到。
java也被归类为解释型语言,这有争议,也有人说java是编译型语言,其实不用太关心java是什么类型的语言,咱们了解下java是怎么编译的,java代码的处理过程和上面讲述的解释型语言编译过程有些相似,可是处理过程要复杂些,分为了两个阶段:编译和解释:
- 编译:首先是像
C++语言同样的编译器,编译java代码,可是和C++编译器生成机器代码不一样,经过编译器先转换成抽象语法树,后转换成字节码,字节码是一种中间代码。 - 解释:而后就是运行字节码,主要依靠的就是
java虚拟机(JVM)加载字节码,使用解释执行这些字节码,将字节码转成机器码。字节码能够不受操做系统和平台的限制,借助java虚拟机也就实现了跨平台的功能,因此一直说java是跨平台的,就是这么跨的。
Java的处理过程加入了JIT的概念,JIT能够将字节码转为本地代码而后执行,会提升执行效率,JIT主要是起到优化性能的做用。不少JavaScript引擎也用到了。
JavaScript被归类弱类型解释型语言,由于是弱类型语言,也能够说是动态类型语言。相比较而言,C++或者java等是静态类型语言,他们在编译的时候就可以知道每一个变量的类型。而JavaScript在编辑的时候无法知道其变量的数据类型,只有在运行的时候才能肯定,这致使JavaScript面临着性能方面的巨大压力。在运行时计算和决定数据类型,会带来很严重的性能损失,这也致使JavaScript运行效率比C++、java要低不少,为了提升运行效率,不少厂商在作努力,目前作的比较好的就是Chrome的V8引擎,V8引擎是JavaScript引擎。
JavaScript的执行是依赖JavaScript引擎,JavaScript引擎相似JVM,是一个专门处理JavaScript脚本的虚拟机,JavaScript引擎目前有不少:SpiderMonkey、JavaScriptCore、Chakra、V8等,现代JavaScript引擎都引入了Java虚拟机和C++编译器的众多技术,和早期的JavaScript引擎工做方式有很大的不一样:
早期由解释器来解释它们便可,就是将源代码转变成抽象语法树,而后在抽象语法树上解释执行,早期的JavaScriptCore就是这样工做的,后面改进了。随着将Java虚拟机的JIT技术引入,如今的作法是将抽象语法树转成中间表示(也就是字节码),而后经过JIT技术转成本地代码。也有些作法直接从抽象语法树生成本地代码的JIT技术,例如早期的V8。
JavaScript引擎
目前如今的JavaScript引擎对JavaScript的处理过程和java类似,毕竟引入了java编译技术,可是仍是有区别,java处理分了两个阶段:编译和解释,经过编译器将源代码解析生成字节码,后在经过JVM将字节码转成机器码后运行。JavaScript引擎编译把编译和解释这两个阶段结合起来了,都在JavaScript引擎中执行,目前JavaScript引擎主要包含如下部分:
- 编译器:将源代码编译成抽象语法树,在某些引擎(如
JavaScriptCore,如今的V8)中还包括将抽象语法树转换成字节码 - 解释器:在某些引擎(如
JavaScriptCore)中,解释器主要是接受字节码,解释执行字节码,但早期V8引擎中没有解释器 JIT工具:将字节码或者抽象语法树转换成本地代码,优化用- 垃圾回收器和分析工具(
profiler):负责垃圾回收和收集引擎中的信息,帮助改善引擎的性能和功效
上图就是JavaScript引擎的编译过程,目前大部分JavaScript引擎都是按照上面的流程对JavaScript进行编译,首先用编译器将源代码转换成抽象语法树而后再转换成字节码,解释器解析执行字节码,生成本地代码。
V8引擎
为何在本文讲述V8引擎的编译过程,V8是一个开源项目,在性能方面要优于其余JavaScript引擎,Chrome 使用的V8引擎,浏览器市场占有率很大,而且Node也是基于V8研发的,V8也支持众多的操做系统和硬件架构,V8具备表明性,V8自08年发布以来,性能一直在稳步的提升:
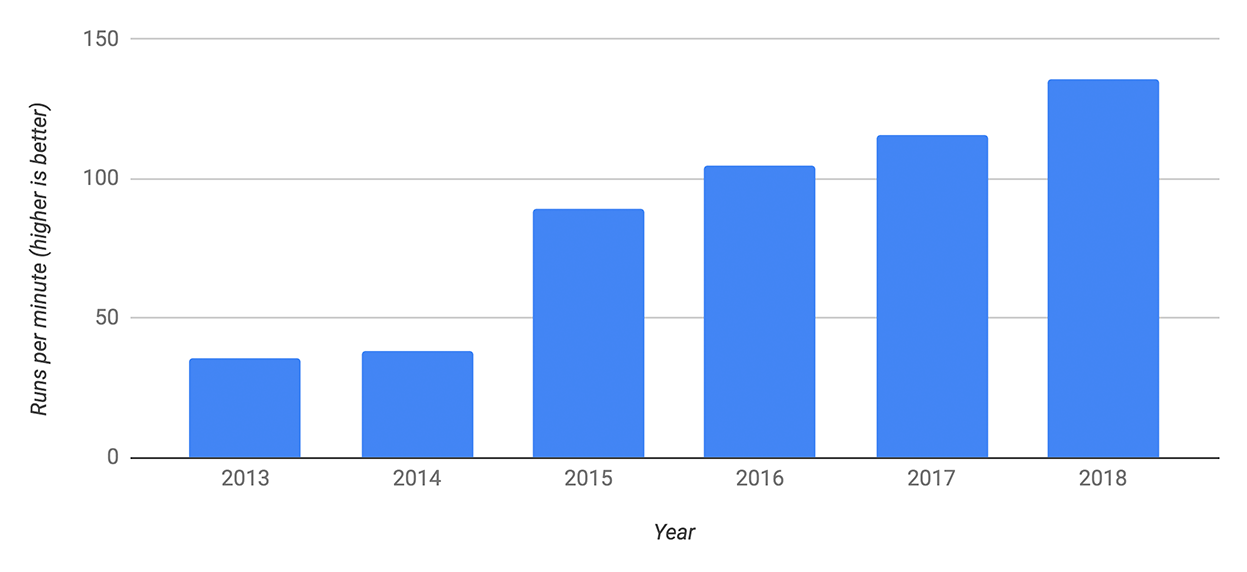
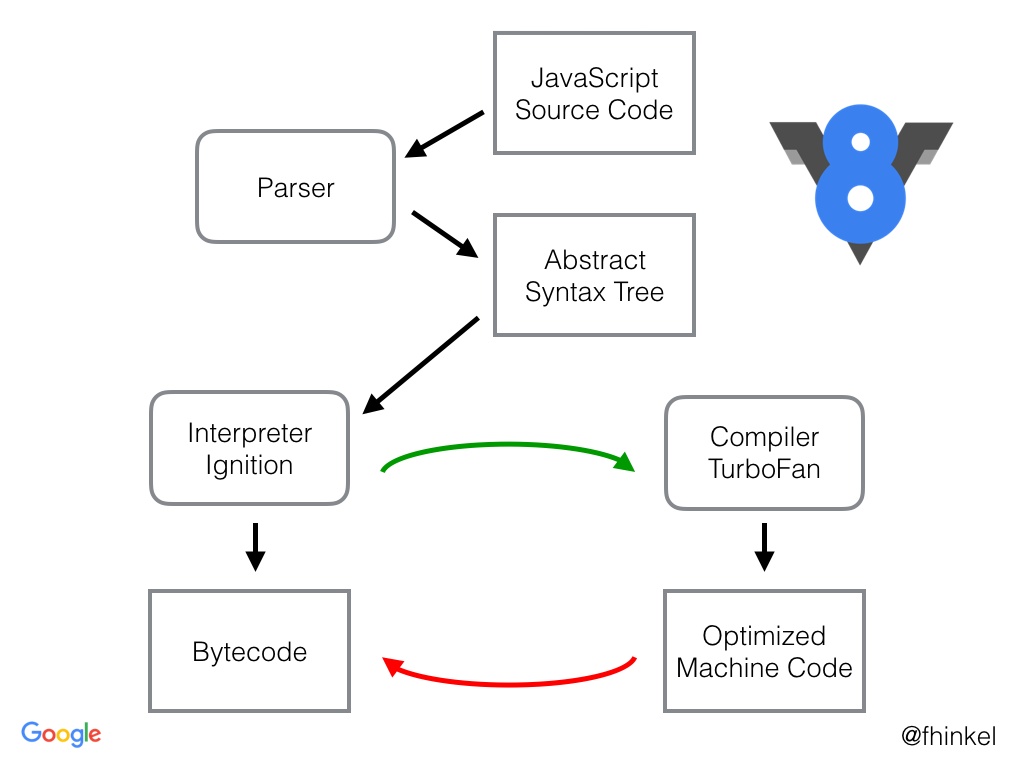
下面是V8引擎执行的整个过程,主要包括了如下几个模块:
parse:负责将JavaScript源代码转换成抽象语法树(AST)Ignition:interpreter,解释器,将AST转换成字节码(Bytecode),解析执行字节码,同时也收集TurboFan优化编译所须要的信息TurboFan:compiler,JIT编译器,利用Ignitio所收集的类型信息,将Bytecode转换为优化的机器码Orinoco:garbage collector,垃圾回收模块,负责将程序再也不须要的内存空间回收
生成抽象语法树
V8引擎首先是经过编译器(parse)将源代码解析抽象语法树(AST),生成AST分为两个阶段,一是词法分析,二是语法分析:
- 词法分析:将源代码拆成最小的、不可再分的词法单元(
token)。例如程序var a = 2;。这段程序一般会被分解成这些词法单元:var、a、=、2、;。五个词法单元。空格是否会被看成词法单元,取决于空格在这门语言是否具备意义,在JavaScript中,空格是不会被看成词法单元。 - 语法分析:这个过程是将词法单元流(数组)转换成一个由元素逐级嵌套所组成的表明了程序语法结构的树,这个树被称为抽象语法树(
AST)。var a = 2;的抽象语法树中可能会有一个叫作VariableDeclaration的顶级节点,接下来是一个叫做Identifier(它的值是a)的子节点,以及一个叫作AssignmentExpression的子节点。AssignmentExpression节点有一个叫作NumericLiteral(它的值是2)的子节点。
上面就是var a = 2生成抽象语法树的一个过程,能够借助在线工具查看。
AST是源代码语法结构的一种抽象表示,计算机不是识别源代码,因此须要将源代码转换成计算机能识别的机器码,AST也只是这一过程当中的一步。
讲到这里,有一个词有必要说起,Babel,前端同窗对这个应该很熟悉,有的ES6语法如今浏览器还不支持,须要将ES6语法转成ES5语法,这一个过程就要借助Babel来实现,Babel是一个JavaScript编译器,分了三个阶段:解析、转译、生成。将ES6源码解析成AST,再将ES6语法的AST转成ES5的AST,最后利用它来生成ES5源代码,这就是Babel的基本实现原理。
ESLint原理也大体相同,检测流程也是将源码转换成AST,在利用AST来检测代码规范。
AST在计算机科学中是一个很重要的概念,须要了解下,能更好的帮助咱们理解本身写的代码。Vue的编译也用到了AST。
生成字节码
上面已经讲述了将JavaScript源代码转换成AST,如今须要将AST转换成字节码。前面有提到早期的V8引擎v5.6版本以前,不会将AST转换成字节码,直接将AST转换成机器码。有两个编译器:
full-codegen:简单且快速的编译器,能够生成简单但相对较慢的机器码Grankshaft:较为复杂的JIT编译器,能够生成高度优化的机器码
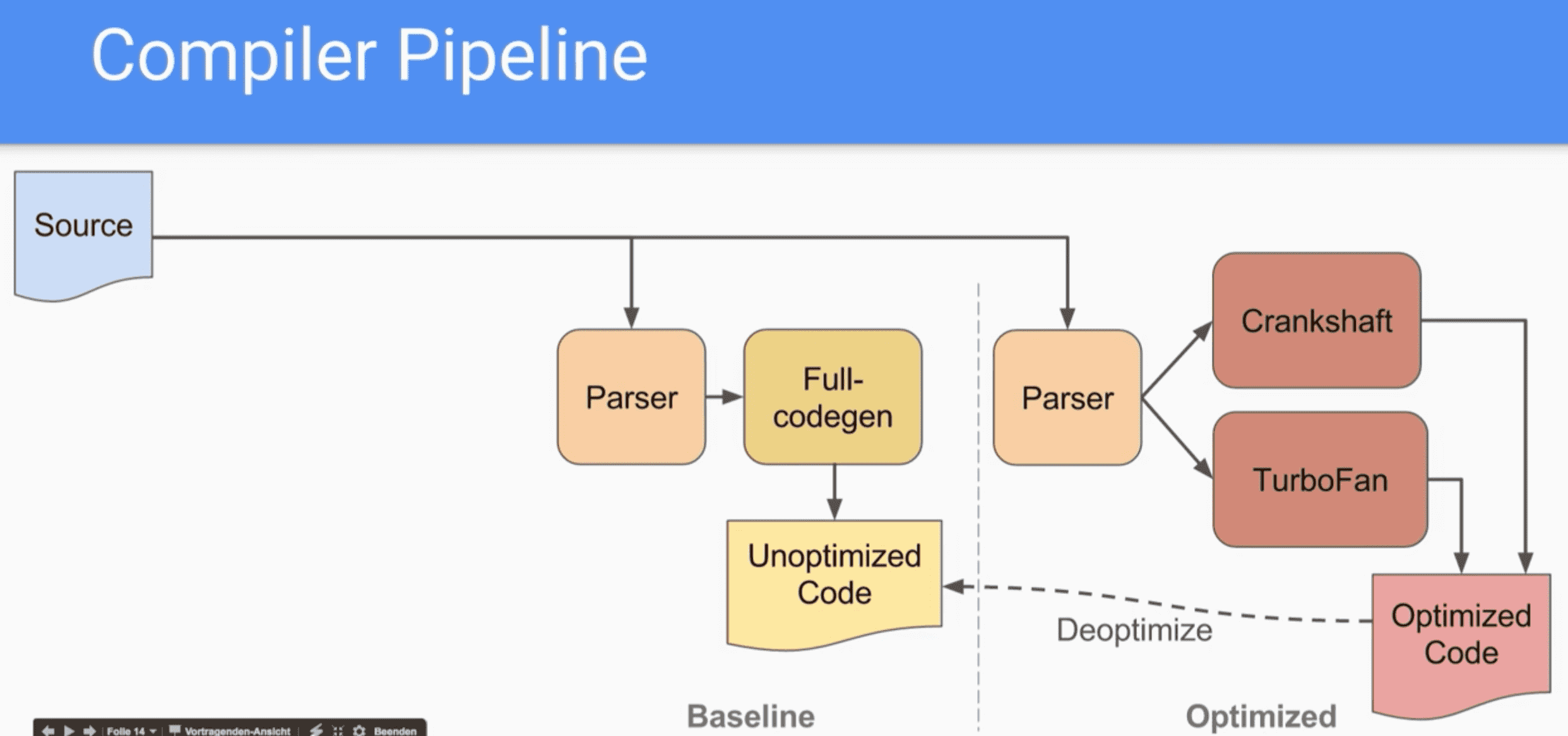
首次执行JavaScript代码,直接经过full-codegen编译器将AST转换成机器码,跳过了转换成字节码这一过程,这样使得它能够很是快速地执行机器码。
这样作的主要目的在于减小转成字节码这一中间过程的转换时间,提升代码的执行速度,这一切也都是在页面加载的时候完成,这样能够提升优化的可能,执行性能会有比较大的提升,可是缺点也很明显:
- 会带来内存占用过大的问题,由于将抽象语法树所有生成了机器码,而机器码相比字节码占用内存大不少
- 某些
JavaScript使用场景使用解释器更为合适,解析成字节码,有些代码不必生成机器码,进而尽量的减小了机器码占用内存过大的问题 - 由于没有中间表示,会减小优化的机会,由于少了一个中间表示层
在发布v5.6版以前,为了作性能优化也作了不少工做,为了减小生成机器码,尝试了大量延迟解析和编译(Lazy parsing and compiling)的工做。例如,对于一段代码,若是这段代码中的函数没有在初始化调用,则该调用过程将会被“延迟”进行,直到第一次函数调用时再编译该函数对应的代码。
经过full-codegen编译器生成机器码后,经过数据分析器(Profiler)采集一些信息,这些信息会提供给Grankshaft编译器。
Grankshaft编译器,主要针对热点代码进行优化。从上面的编译过程能够看到,该编译器也是基于源代码进行分析,同时构建Hydroger图并基于此来进行优化分析最,终生成更高效的机器码,这是一个逐步渐进的优化过程。同时,当发现优化后代码的性能还不如未优化的代码,V8将退回原来的代码,也就是反优化。
尽管一直在作优化,可是优化层仍是在机器码上,机器码自己占用内存就很大。Grankshaft编译器虽然也是作JIT优化的,可是Grankshaft每次解析仍是从源代码从新解析的。
后面官方在V8的v5.6版仍是将AST转换成字节码这一过程加上了,回到了字节码的怀抱中。引进了Ignition解释器,经过Ignition解释器将AST转换成字节码。
V8从新引进Ignition解释器,将AST转换成字节码后,内存占用显著降低了,同时也可使用JIT编译器作进一步的优化。
上图就是十大流行手机端网站的测试,能够发现他们的内存占用显著降低。
字节码是介于AST和机器码之间的一种代码,须要将其转换成机器码后才能执行,字节码能够理解为是机器码的一种抽象。不太须要具体理解字节码是什么,只须要知道这是个中间代码。
Ignition设计的目的是为V8创建一个解释器来执行低层级的字节码,以便让哪些只被运行一次或者非热点的代码以字节码的形式更加紧凑的存储。因为字节码更小,编译的时间也将大幅减小。同时字节码可以直接传给TurboFan图生成器,从而在TurboFan里面优化函数时,能够避免从新解析JavaScript源代码。也就是说TurboFan的编译是基于字节码,而不是源代码。
Ignition解释器的引入也就彻底替代了full-codegen,Crankshaft也被彻底抛弃了,Crankshaft不能解析优化字节码,后面被TurboFan编译器替代了。
生成机器码
Ignition解释器除了能够快速生成未优化的字节码外,还负责执行字节码。第一次执行字节码时,也会收集分析数据,解释器会逐条解释。若是发现hot代码(即一段代码被重复执行屡次),生成的字节码和分析数据则会被传给TurboFan编译器,它会依据分析数据生成高度优化的机器码。当再次执行这段代码时,只须要执行编译后的机器码。
TurboFan编译器是JIT优化编译器,开始在Ignition解释器中运行字节码。在某些时候,引擎肯定代码很热并启动TurboFan前端,这是TurboFan的一部分,它处理集成分析数据和构建代码的基本机器表示。而后将其发送到另外一个线程上的TurboFan,以进一步改进代码。V8引擎是多线程的,TurboFan编译和生成字节码不在同一个线程上。
在TurboFan运行时,V8会继续在Ignition解释器中执行字节码。在某个时候,TurboFan已经完成,有了可执行的机器码,可与之继续执行。
由Ignition解释器收集的分析数据被TurboFan使用,主要是经过一种称为推测优化(Speculative Optimization)的技术生成高度优化的机器码。TurboFan会查看过去看到的值类型,并假设未来咱们将看到相同类型的值,这可使得TurboFan省去不少不须要处理的状况。若是假设失败了,那么就会返回到解析字节码,这也就是反优化(deoptimization)。
到这里把V8对JavaScript的编译过程大体的讲完了,如今在回过头再看下面这张图应该也很清楚了。没有很详细讲解各个步骤,V8引擎涉及到的东西太多了,短期内也比较难的把V8整个内容梳理出来,这也不是一篇文章能讲清楚,考虑接下来的文章中尽量的以V8的角度来写。
目前现代JavaScript引擎的编译过程大部分都是相似的,核心原理是一致的,主要区别在于不一样的引擎有不一样的优化层,意思就是不一样的引擎解释器和编译器的数量不同,主要在于使用解释器快速生成代码或者使用优化编译器生成高校代码之间存在一个基本权衡。经过添加更多优化层让咱们作出更细粒度的决策,可是以额外的复杂性和开销为代价。此外,在优化级别和生成代码所占用的内存之间也存在折衷。其实归根结底为了让引擎性能更优。感兴趣的同窗能够本身去了解下其余引擎的编译过程~
到这里,还没回答开篇提出来的问题,为何会将数据类型分为基础类型和引用类型,这和引擎的内存管理有关,关于V8的内存管理,下篇文章和你们一块儿聊聊,内容也不少。
结语
文章若有不正确的地方欢迎各位大佬指正,也但愿有幸看到文章的同窗也有收获,一块儿成长!
--------------------------本文首发于我的公众号---------------------
- 1. 编译过程
- 2. openwrt编译过程
- 3. OpenWRT 编译过程
- 4. c++编译过程
- 5. Android编译过程
- 6. android 编译过程
- 7. C++编译过程
- 8. APP编译过程
- 9. gcc 编译过程
- 10. GCC编译过程
- 更多相关文章...
- • Eclipse 编译项目 - Eclipse 教程
- • Rust 并发编程 - RUST 教程
- • Java 8 Stream 教程
- • YAML 入门教程
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. CVPR 2020 论文大盘点-光流篇
- 2. Photoshop教程_ps中怎么载入图案?PS图案如何导入?
- 3. org.pentaho.di.core.exception.KettleDatabaseException:Error occurred while trying to connect to the
- 4. SonarQube Scanner execution execution Error --- Failed to upload report - 500: An error has occurred
- 5. idea 导入源码包
- 6. python学习 day2——基础学习
- 7. 3D将是页游市场新赛道?
- 8. osg--交互
- 9. OSG-交互
- 10. Idea、spring boot 图片(pgn显示、jpg不显示)解决方案
- 1. 编译过程
- 2. openwrt编译过程
- 3. OpenWRT 编译过程
- 4. c++编译过程
- 5. Android编译过程
- 6. android 编译过程
- 7. C++编译过程
- 8. APP编译过程
- 9. gcc 编译过程
- 10. GCC编译过程