Protocol Buffers 序列化协议及应用
Protocol Buffers是Google开发一种数据描述语言,可以将结构化数据序列化,可用于数据存储、通讯协议等方面。据Google官方文档介绍,如今Google内部已经有48,162个消息类型定义在12,183个proto文件中。本文会从快速入门、语言规范、编码协议、性能评估等几个方面对Prototol Buffers进行介绍。java


不了解Protocol Buffers的同窗能够把它理解为更快、更简单、更小的JSON或者XML,区别在于Protocol Buffers是二进制格式,而JSON和XML是文本格式。python

相对于XML,Protocol Buffers的具备以下几个优势:git
- 简洁
- 体积小:消息大小只须要XML的1/10 ~ 1/3
- 速度快:解析速度比XML快20 ~ 100倍
- 使用Protocol Buffers的编译器,能够生成更容易在编程中使用的数据访问代码
- 更好的兼容性,Protocol Buffers设计的一个原则就是要可以很好的支持向下或向上兼容。

看一个简单的对比例子,表达一个用户的三个基本的属性,若是使用XML消息体大小为82 bytes。github
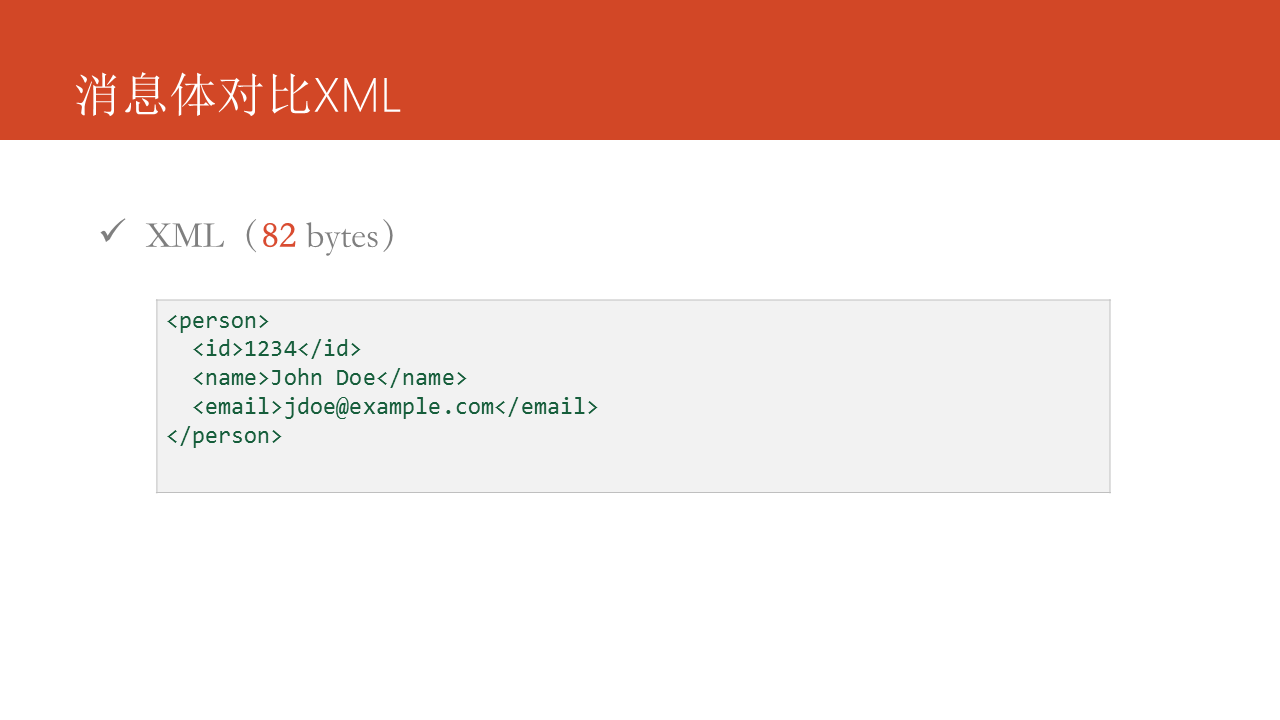
若是使用JSON消息体大小为56 bytes。编程

使用Protocol Buffers咋则只须要 31 bytes,看到这些二进制数据你们能够暂时忽略,后面会具体分析这些二进制数据是如何编码的。json

接下来先看一个简单的入门示例,在该例子中咱们从准备环境开始,编写proto文件,到最后使用Protocol Buffers编译器生成代码,再到具体的使用。ruby

从https://github.com/google/protobuf下载编译安装protoc,并下载Protobuf SDK。框架
开始编写proto文件,使用message关键字定义消息类型,消息中每一个字段须要指定字段类型和字段序号。同一个message中字段性能

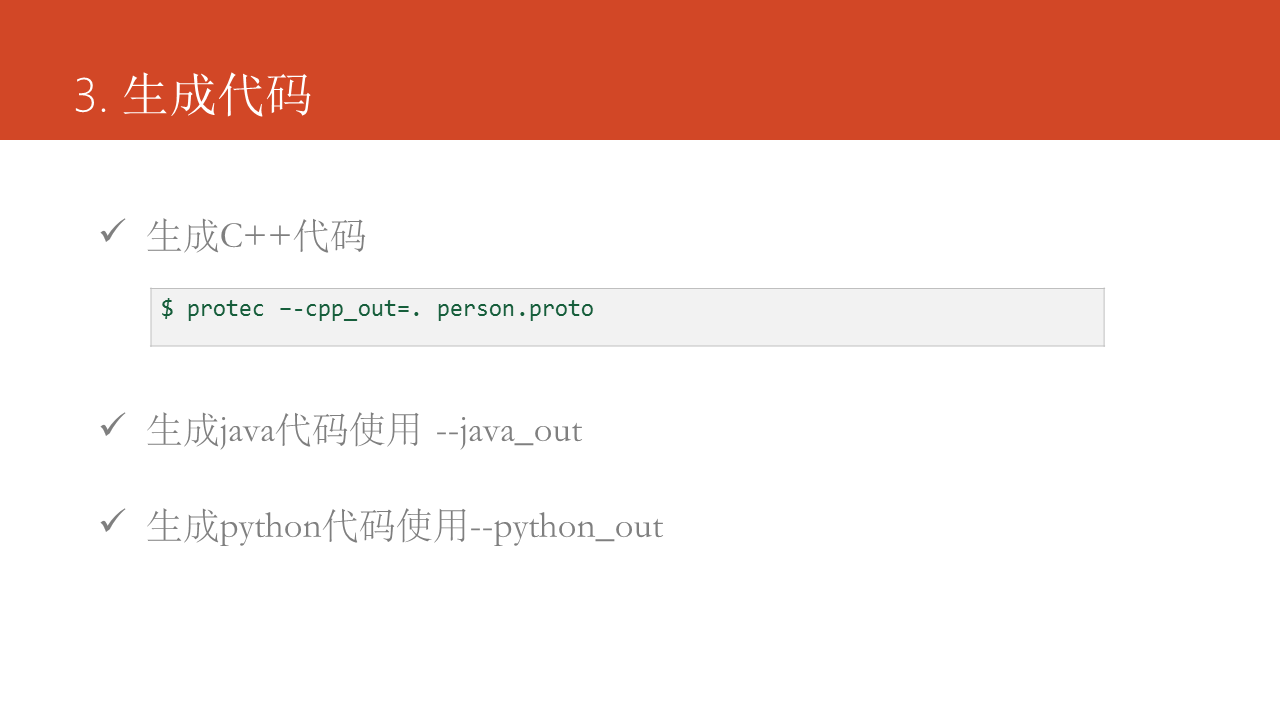
使用protoc命令生成代码,使用--cpp_out、--java_out、--python_out命令选项能够生成C++、Java、Python代码,在最新版本Protocol Buffers v3中还加入了ruby语言的支持。测试
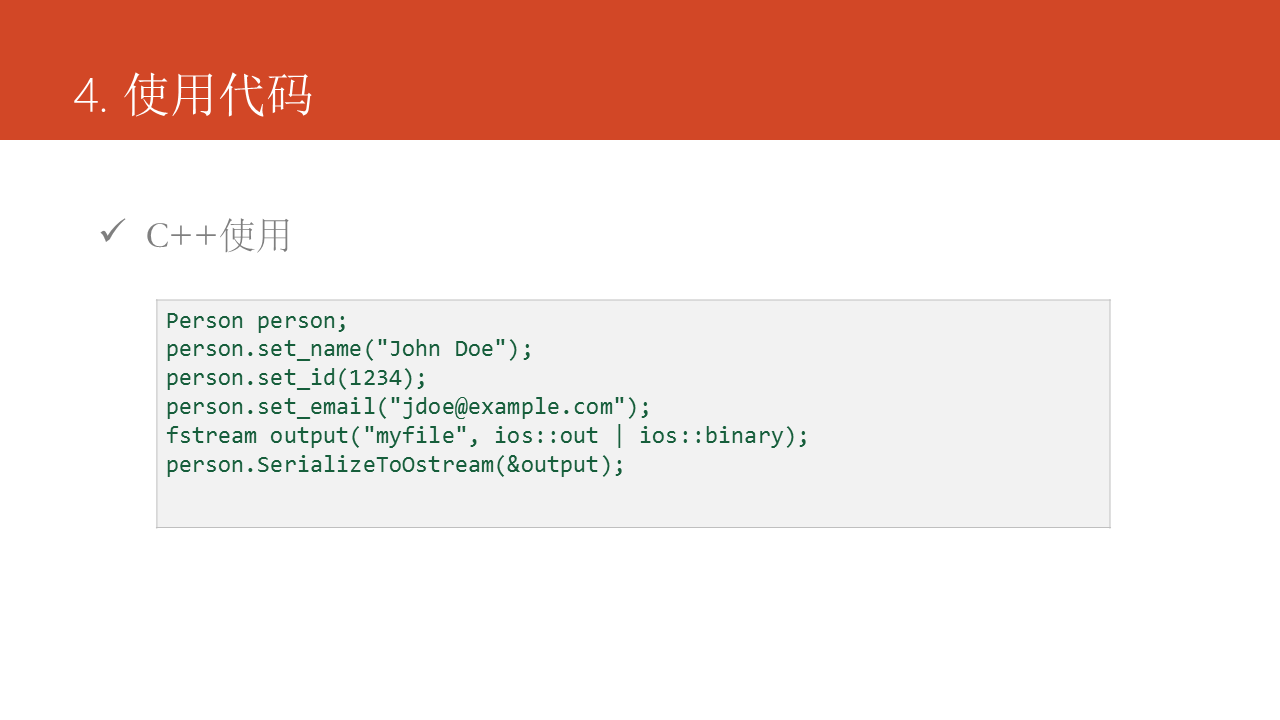
生成代码的代码能够直接加入到本身的代码工程中使用,以C++语言为例:
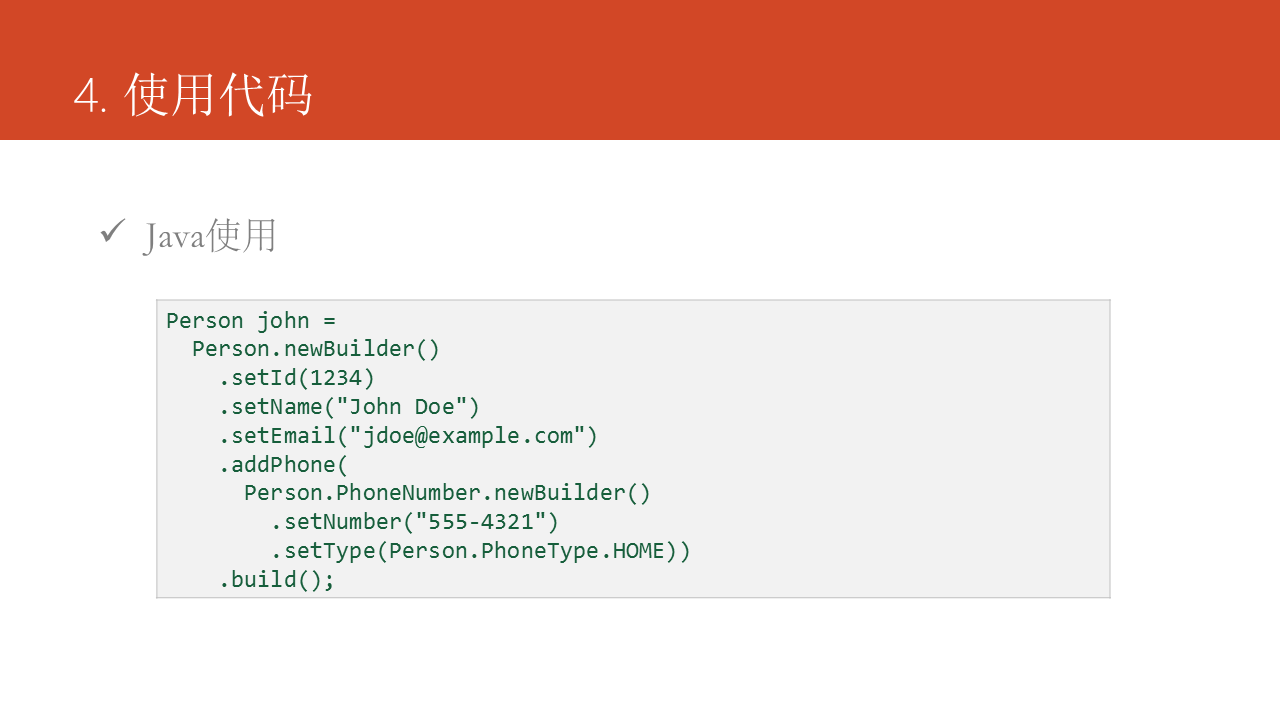
这是一段Java语言的使用示例:
接下来会详细说明如何定义proto文件:

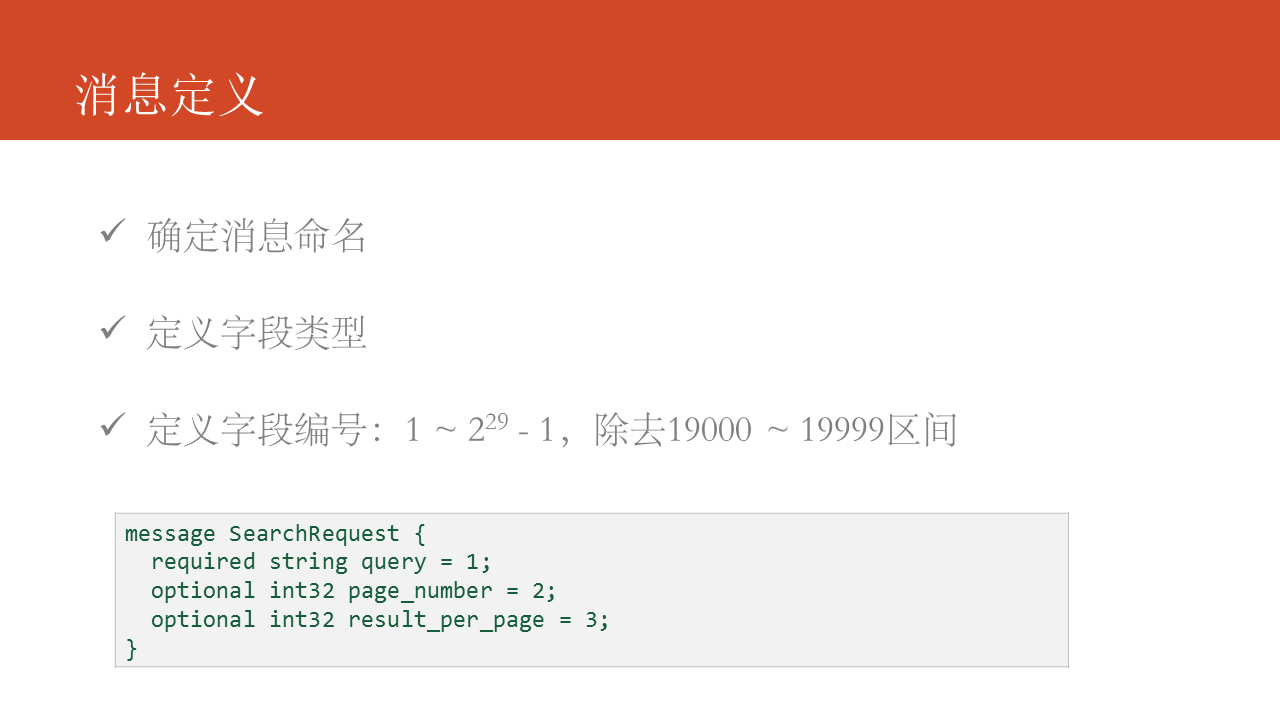
在消息定义中,咱们须要肯定三个问题:
- 肯定消息命名,给消息取一个有意义的名字。
- 指定字段的类型
- 定义字段的编号,在Protocol Buffers中,字段的编号很是重要,字段名仅仅是做为参考和生成代码用。须要注意的是字段的编号区间范围,其中19000 ~ 19999被Protocol Buffers做为保留字段。
字段约束,required指定该字段必须赋值,禁止为空(在v3中该约束被移除);optional指定字段为可选字段,能够为空,对于optional字段还可使用[default]指定默认值,若是没有指定,则会使用字段类型的默认值;使用repeated指定字段为集合。

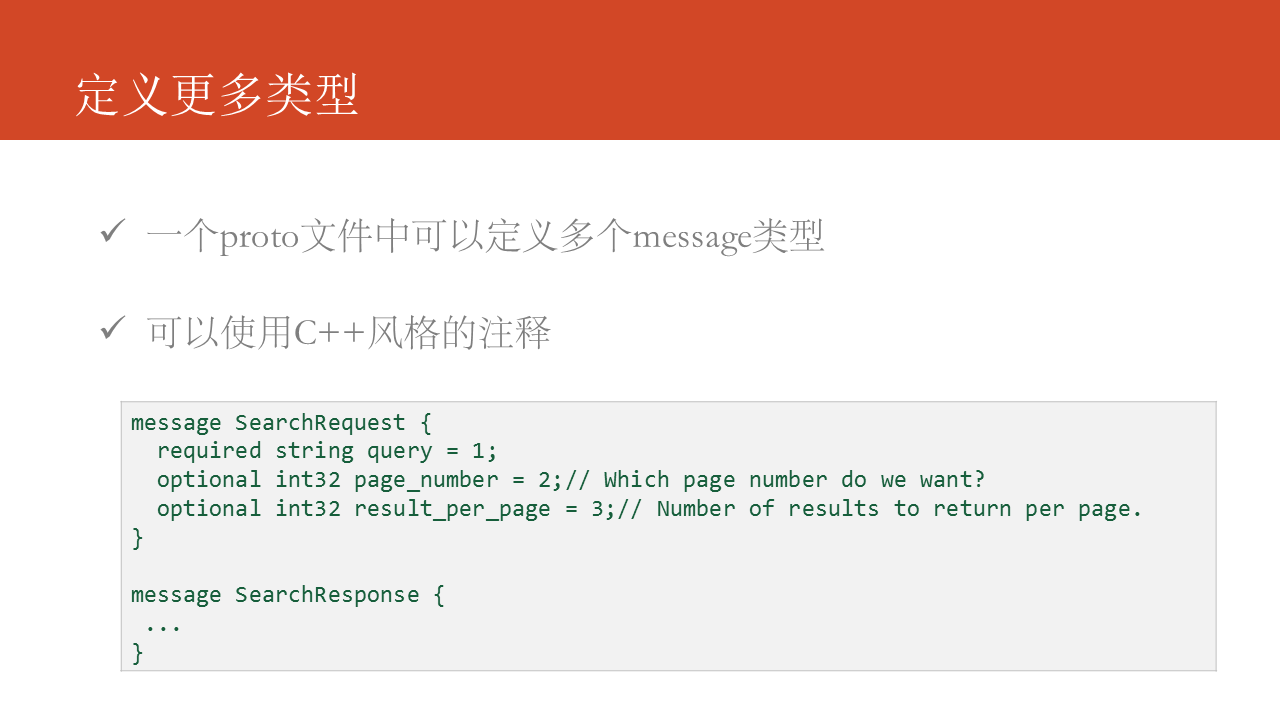
在一个proto文件中能够同时定义多个message类型,生成代码时根据生成代码的目标语言不一样,处理的方式不太同样,如Java会针对每一个message类型生成一个.java文件。还可使用C++风格的注释。
在Protocol Buffers中提供了不少的标量类型,供咱们在定义字段类型时使用。

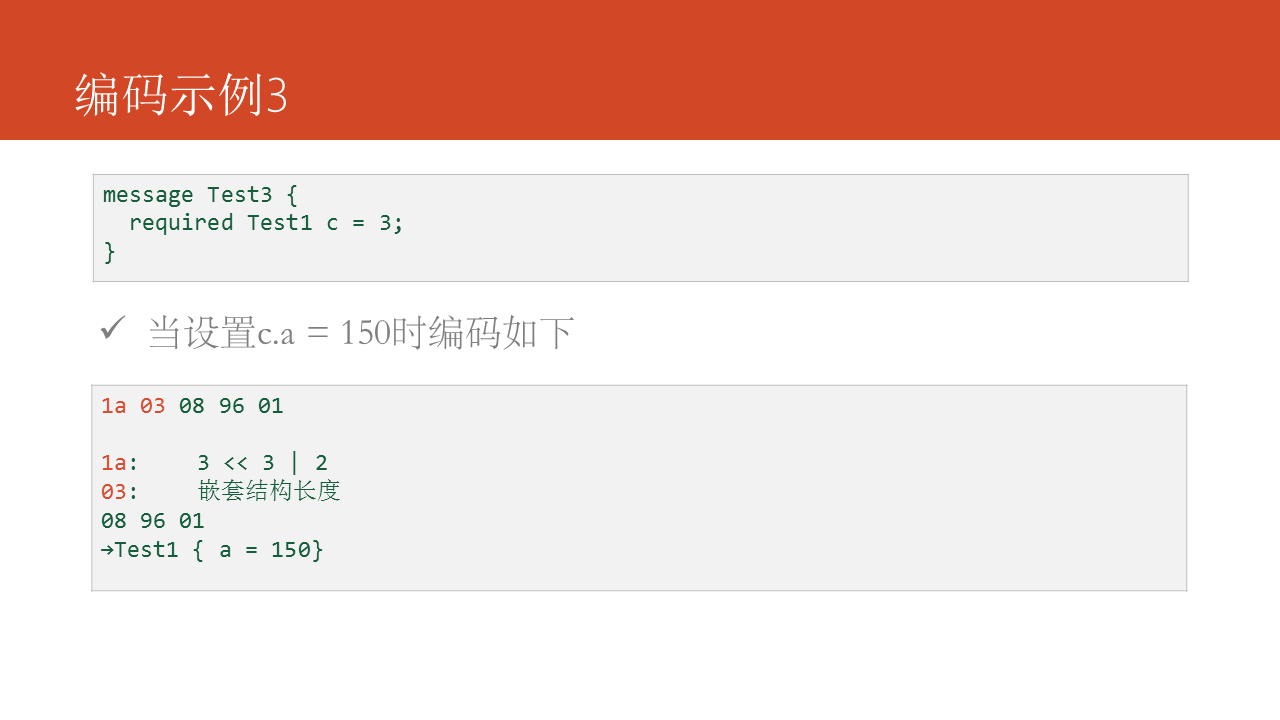
能够指定字段的类型为其余message类型,如图中的示例代码所示:

还可使用import关键字导入其余proto文件,这有利于你进行本身的proto文件的规划和整理。

在proto文件中消息的类型还能够嵌套,如你定义的message类型仅做为另一个Message的字段类型。

为了便于扩展,在proto文件中可使用extensions关键字预留一部分字段编号出来,以便于后期给第三方扩展时使用。

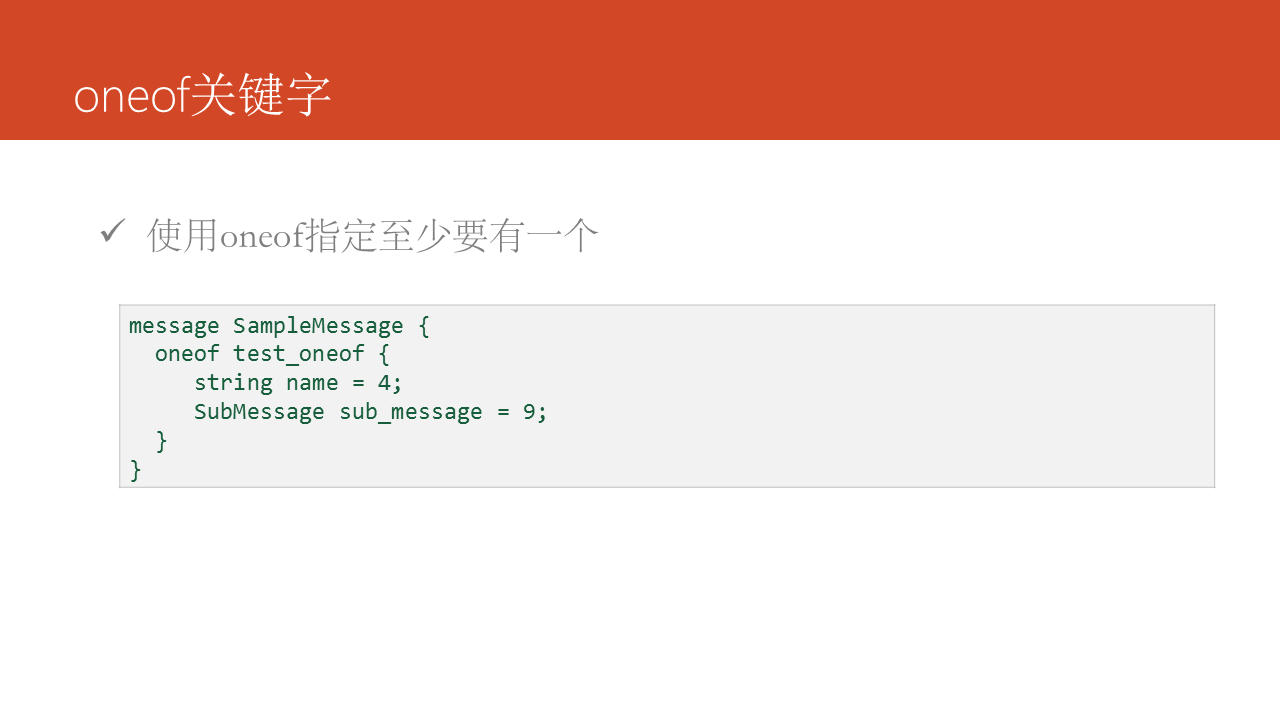
oneof关键字指定一组字段中,至少要有一个字段必须赋值。如在用户登陆系统中,使用邮箱和用户名均可以登陆该系统,因此一般会要求至少提供用户名或者邮箱。
在这一部分总咱们会仔细分析,Protocol Buffers序列化后的二进制代码的编码协议,不知道这些并不会影响咱们使用Protocol Buffers,可是了解以后有助于咱们更好的使用Protocol Buffers和进行调试。

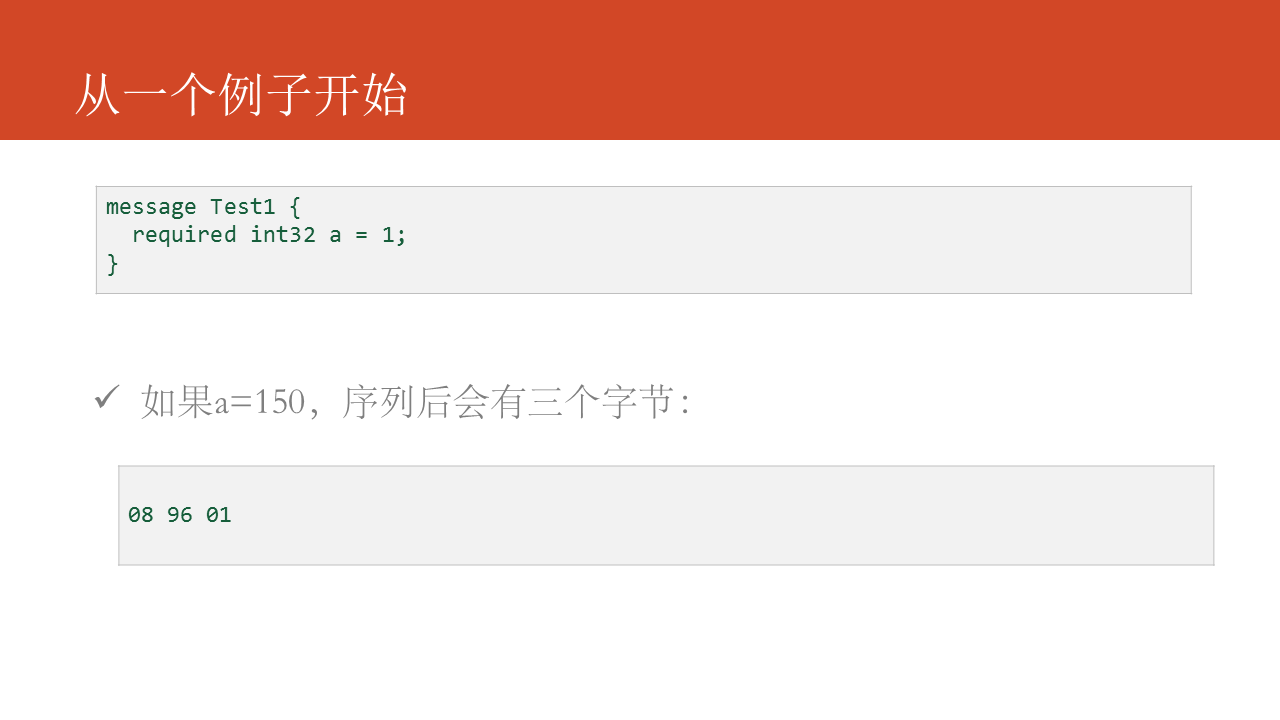
先从一个简单的例子开始,如图中的代码所示,咱们有这样一个消息定义,在使用中给a赋值为150,最终编码获得的结果是 08 96 01,为何编码的结果是这样,其中08又表明什么?后续一一为你介绍。
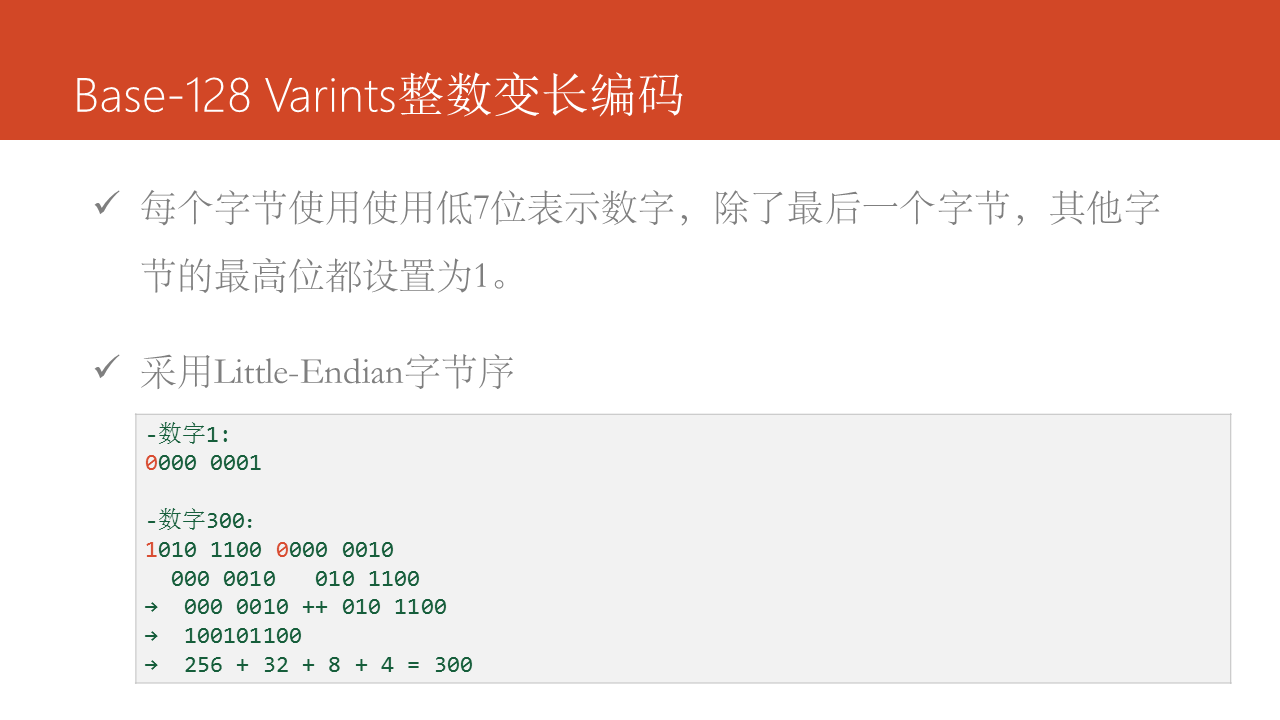
在Protocol Buffers中采用Base-128变长编码,所谓变长编码是和定长编码相对的,定长编码使用固定字节数来表示,如int32类型的数字固定使用4 bytes表示,而变长编码是须要几个字节就使用几个字节,如对于int32类型的数字1来讲,只须要1 bytes足够。Base-128变长编码的原则就两条:
- 每一个字节使用使用低7位表示数字,除了最后一个字节,其余字节的最高位都设置为1。
- 采用Little-Endian字节序
一个Protocol Buffers的消息包含一系列字段key/value,每一个字段由一个变长32位整数做为字段头,后面跟随字段体。字段头的格式以下:
(field_number << 3) | wire_type -field_number: 字段序号 -wire_type: 字段编码类型

这里是详细的字段说明,其中三、4已经放弃:



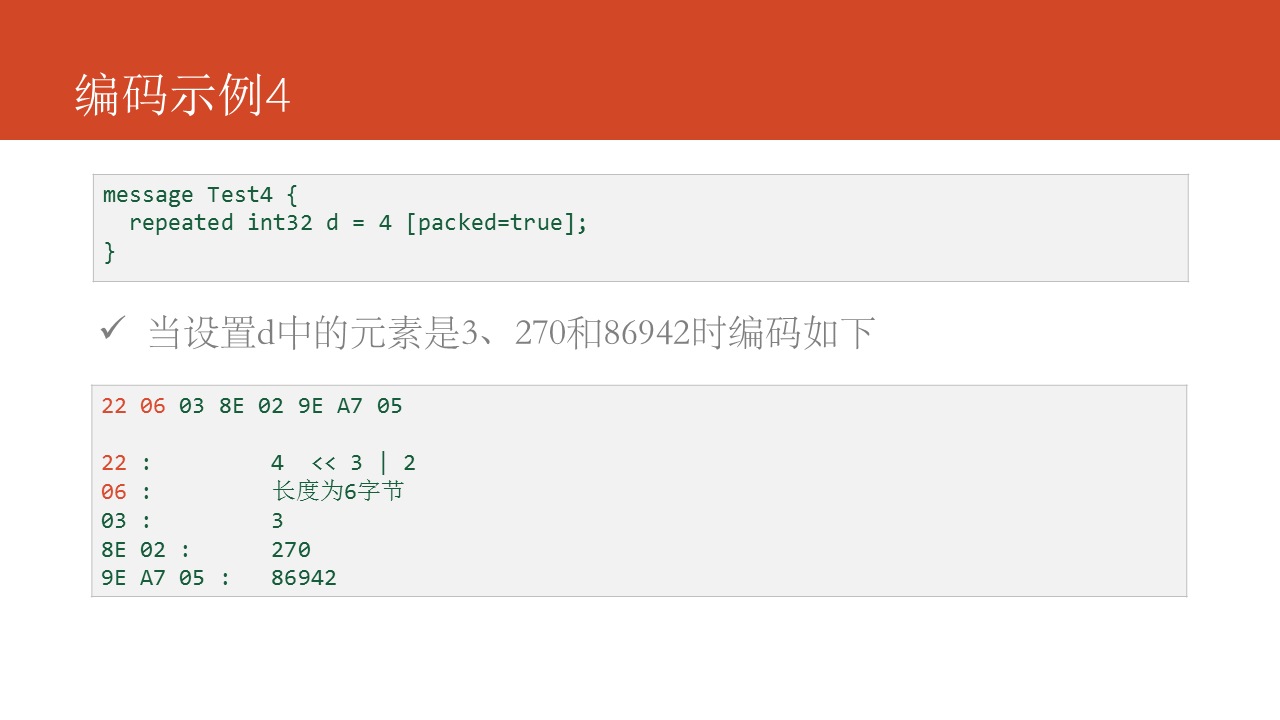

接下来咱们对Protocol Buffers的性能作一些测试。

在测试过程当中,咱们使用一个统一的消息体格式,主要评估如下两个性能指标:
- 序列化速度
- 报文大小


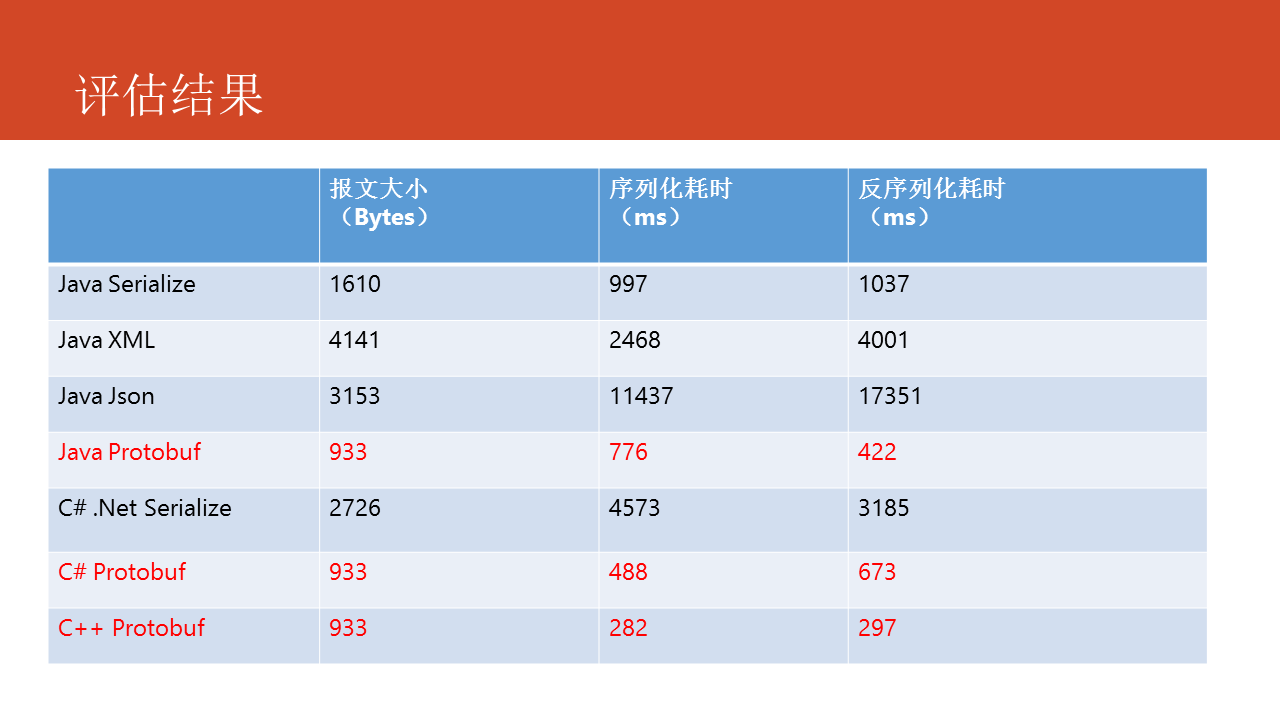


尽管Protocol Buffers有序列化速度快、报文体积小以及更好的兼容性等优势,但同时也有一些缺点,在使用时要根据实际状况来选择使用。
- 缺少自描述,可读性差,可使用TextFormat
- 适用于内部服务和存储,而不适合直接对外公开,如Open API,protobuf v3将加入对json的支持,可解决此问题

与Protocol Buffers相似的框架有微软出的Bond和Facebook出的Thrift,感兴趣的同窗能够去下载研究一下。

- 1. protocol buffers 序列化数据
- 2. Protocol Buffers
- 3. 【协议】MessagePack, Protocol Buffers和Thrift序列化框架原理和比较说明
- 4. Protocol Buffers 学习
- 5. Protocol buffer序列化及其在微信蓝牙协议中的应用
- 6. Protocol Buffers 简介
- 7. Protocol Buffers (protobuf)简介
- 8. Google Protocol Buffers 概述
- 9. protobuf【protocol buffers】详解
- 10. Dubbo协议及序列化
- 更多相关文章...
- • XML 应用程序 - XML 教程
- • ASP.NET MVC - Internet 应用程序 - ASP.NET 教程
- • 适用于PHP初学者的学习线路和建议
- • Flink 数据传输及反压详解
-
每一个你不满意的现在,都有一个你没有努力的曾经。