Mongodb Geo2d索引原理
腾讯云技术社区-掘金主页持续为你们呈现云计算技术文章,欢迎你们关注!javascript
做者:孔德雨java
Mongodb的geo索引是其一大特点,本文从原理层面讲述geo索引中的2d索引的实现mongodb
2d 索引的建立与使用
经过 架构
db.coll.createIndex({"lag":"2d"}, {"bits":int}))复制代码
来建立一个2d索引,索引的精度经过bits来指定,bits越大,索引的精度就越高。更大的bits带来的插入的overhead能够忽略不计。测试
经过大数据
db.runCommand({
geoNear: tableName,
maxDistance: 0.0001567855942887398,
distanceMultiplier: 6378137.0,
num: 30,
near: [ 113.8679388183982, 22.58905429302385 ],
spherical: true|false})复制代码
来查询一个索引,其中spherical:true|false 表示应该如何理解建立的2d索引,false表示将索引理解为平面2d索引,true表示将索引理解为球面经纬度索引。这一点比较有意思,一个2d索引能够表达两种含义,而不一样的含义是在查询时被理解的,而不是在索引建立时。优化
2d索引的理论
Mongodb 使用一种叫作Geohash的技术来构建2d索引,可是Mongodb的Geohash并无使用国际通用的每一层级32个grid的Geohash描述方式(见wiki geohash)。而是使用平面四叉树的形式。以下图:ui

很显然的,一个2bits的精度能把平面分为4个grid,一个4bits的精度能把平面分为16个grid。2d索引的默认精度是长宽各为26,索引把地球分为(2^26)(2^26)块,每一块的边长估算为云计算
2*PI*6371000/(1<<26) = 0.57 米复制代码
mongodb的官网上说的60cm的精度就是这么估算出来的:spa
By default, a 2d index on legacy coordinate pairs uses 26 bits of precision, which is roughly equivalent to 2 feet or 60 centimeters of precision using the default range of -180 to 180.
2d索引在Mongodb中的存储
上面咱们讲到Mongodb使用平面四叉树的方式计算Geohash。事实上,平面四叉树仅存在于运算的过程当中,在实际存储中并不会被使用到。
插入
对于一个经纬度坐标[x,y],MongoDb计算出该坐标在2d平面内的grid编号,该编号为是一个52bit的int64类型,该类型被用做btree的key,所以实际数据是按照 {GeoHashId->RecordValue}的方式被插入到btree中的。
查询
对于geo2D索引的查询,经常使用的有geoNear和geoWithin两种。geoNear查找距离某个点最近的N个点的坐标并返回,该需求能够说是构成了LBS服务的基础(陌陌,滴滴,摩拜), geoWithin是查询一个多边形内的全部点并返回。咱们着重介绍使用最普遍的geoNear查询。
geoNear的查询过程
geoNear的查询语句以下:
db.runCommand(
{
geoNear: "places", //table Name
near: [ -73.9667, 40.78 ] , // central point
spherical: true, // treat the index as a spherical index
query: { category: "public" } // filters
maxDistance: 0.0001531 // distance in about one kilometer
}
)复制代码
geoNear能够理解为一个从起始点开始的不断向外扩散的环形搜索过程。以下图所示:
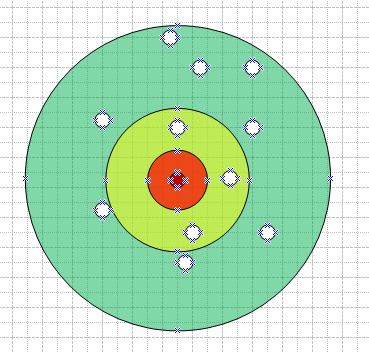
因为圆自身的性质,外环的任意点到圆心的距离必定大于内环任意点到圆心的距离,因此以圆环进行扩张迭代的好处是:
1)减小须要排序比较的点的个数
2)可以尽早发现知足条件的点从而返回,避免没必要要的搜索
集密度估算
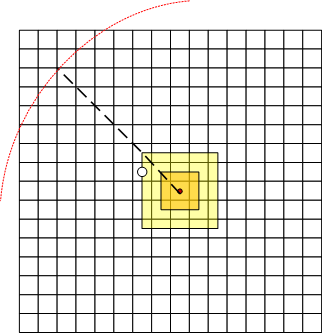
那么,如何肯定初始迭代步长呢,mongoDB认为初始迭代步长和点集密度相关。
geoNear 会根据点集的密度来肯定迭代的初始步长。估算步骤以下:
1)从最小步长默认为60cm向外以矩形范围搜索,若是范围内有至少一个点,则中止搜索,转3)不然转 2)
2)步长倍增,继续步骤1)
3)以矩形对角线长度的三倍做为初始迭代步长。
圆环覆盖与索引前缀原理
上面咱们说过,每一次的搜索都是以圆环为单位进行的,可是真实存入Btree中的是{GeoHashId->RecordValue},计算出与圆环相交的全部边长60cm的格子的GeoHash的值并在Btree中搜素绝对是一个很是愚蠢的作法,由于若是圆环的面积很大,光是枚举全部的GeoHash就有上百万个*。
可是换个角度来看,其实以地球为一个总体去看待存储的点,绝对是稀疏的。这个稀疏的性质使得咱们能够粗略的以平面四叉树的角度自上而下的找出与圆环相交的四叉树中间节点。
整个平面与圆环必然是相交的,因而将平面一分为四,剔除不相交的部分,对于每一个留下来的子平面,继续一分为四,剔除不相交的部分,通过多轮迭代,留下来的子平面的GeoHash都是该子平面中全部grid的索引前缀,以下面四幅图所示:
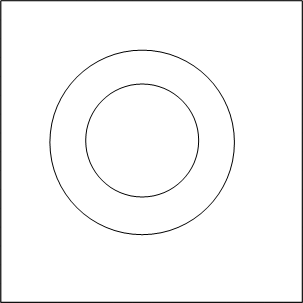
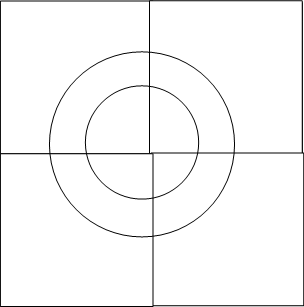
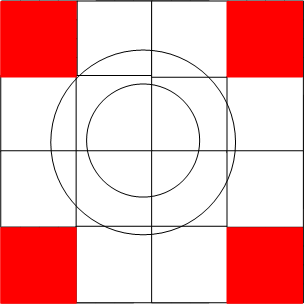

上面四幅图中,分别为整个平面被四叉树划分0,1,2,3次后与圆环的相交状况,若是继续往下细分,所造成的图形就愈来愈逼近整个圆环。MongoDB中使用参数internalGeoNearQuery2DMaxCoveringCells来限制最多逼近到多少个子平面与圆环相交,默认为16。
咱们注意到,上述平面划分过程为四叉树的分裂过程,每一次分裂都使得递归搜索的子平面与父平面有相同的GeoHash前缀(这里须要思考为何,可能不太明显),所以每个子平面能够对应于BTree中一段连续的Range(这里又是为何?),也正所以,该参数越大,会使得须要搜索的子平面越少,可是会使得Btree的Range搜索更趋向于随机化搜索,致使更多的IO。咱们知道Btree更适合于作Range搜索,因此对该参数的调整须要慎重。
展望
MongoDB原生的geoNear接口是国内各大LBS应用的主流选择。腾讯云的MongoDB专家通过测试发现,在点集稠密的状况下,MongoDB原生的geoNear接口效率会急剧降低,单机甚至不到1000QPS。腾讯云MongoDB对此进行了持续的优化,在不影响效果的前提下,geoNear的效率有10倍以上的提高,建议你们选择腾讯云MongoDB最为LBS应用的存储方案。
相关推荐
MongoDB复制集原理
基于用户画像大数据的电商防刷架构
MongoDb Mmap引擎分析
- 1. M14-MongoDB索引原理及使用
- 2. 索引原理
- 3. Mongodb地理空间索引
- 4. Mongodb 地理位置索引
- 5. mongoDB 学习笔记(四)索引 索引管理 空间索引
- 6. MongoDB 索引
- 7. [MongoDB]索引
- 8. MongoDB的索引
- 9. mongoDB 索引
- 10. Mongodb索引
- 更多相关文章...
- • SQLite 索引(Index) - SQLite教程
- • MySQL索引简介 - MySQL教程
- • ☆技术问答集锦(13)Java Instrument原理
- • Java Agent入门实战(三)-JVM Attach原理与使用
-
每一个你不满意的现在,都有一个你没有努力的曾经。
- 1. M14-MongoDB索引原理及使用
- 2. 索引原理
- 3. Mongodb地理空间索引
- 4. Mongodb 地理位置索引
- 5. mongoDB 学习笔记(四)索引 索引管理 空间索引
- 6. MongoDB 索引
- 7. [MongoDB]索引
- 8. MongoDB的索引
- 9. mongoDB 索引
- 10. Mongodb索引