Spring Boot+SQL/JPA实战悲观锁和乐观锁
最近在公司的业务上遇到了并发的问题,而且仍是很常见的并发问题,算是低级的失误了。因为公司业务相对比较复杂且不适合公开,在此用一个很常见的业务来还原一下场景,同时介绍悲观锁和乐观锁是如何解决这类并发问题的。java
公司业务就是最多见的“订单+帐户”问题,在解决完公司问题后,转头一想,个人博客项目Fame中也有一样的问题(虽然访问量根本彻底不须要考虑并发问题...),那我就拿这个来举例好了。mysql
业务还原
首先环境是:Spring Boot 2.1.0 + data-jpa + mysql + lombokgit
数据库设计
对于一个有评论功能的博客系统来讲,一般会有两个表:1.文章表 2.评论表。其中文章表除了保存一些文章信息等,还有个字段保存评论数量。咱们设计一个最精简的表结构来还原该业务场景。github
article 文章表web
| 字段 | 类型 | 备注 |
|---|---|---|
| id | INT | 自增主键id |
| title | VARCHAR | 文章标题 |
| comment_count | INT | 文章的评论数量 |
comment 评论表算法
| 字段 | 类型 | 备注 |
|---|---|---|
| id | INT | 自增主键id |
| article_id | INT | 评论的文章id |
| content | VARCHAR | 评论内容 |
当一个用户评论的时候,1. 根据文章id获取到文章 2. 插入一条评论记录 3. 该文章的评论数增长并保存spring
代码实现
首先在maven中引入对应的依赖sql
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.0.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
复制代码
而后编写对应数据库的实体类数据库
@Data
@Entity
public class Article {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private Long commentCount;
}
复制代码
@Data
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long articleId;
private String content;
}
复制代码
接着建立这两个实体类对应的Repository,因为spring-jpa-data的CrudRepository已经帮咱们实现了最多见的CRUD操做,因此咱们的Repository只须要继承CrudRepository接口其余啥都不用作。服务器
public interface ArticleRepository extends CrudRepository<Article, Long> {
}
复制代码
public interface CommentRepository extends CrudRepository<Comment, Long> {
}
复制代码
接着咱们就简单的实现一下Controller接口和Service实现类。
@Slf4j
@RestController
public class CommentController {
@Autowired
private CommentService commentService;
@PostMapping("comment")
public String comment(Long articleId, String content) {
try {
commentService.postComment(articleId, content);
} catch (Exception e) {
log.error("{}", e);
return "error: " + e.getMessage();
}
return "success";
}
}
复制代码
@Slf4j
@Service
public class CommentService {
@Autowired
private ArticleRepository articleRepository;
@Autowired
private CommentRepository commentRepository;
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
if (!articleOptional.isPresent()) {
throw new RuntimeException("没有对应的文章");
}
Article article = articleOptional.get();
Comment comment = new Comment();
comment.setArticleId(articleId);
comment.setContent(content);
commentRepository.save(comment);
article.setCommentCount(article.getCommentCount() + 1);
articleRepository.save(article);
}
}
复制代码
并发问题分析
从刚才的代码实现里能够看出这个简单的评论功能的流程,当用户发起评论的请求时,从数据库找出对应的文章的实体类Article,而后根据文章信息生成对应的评论实体类Comment,而且插入到数据库中,接着增长该文章的评论数量,再把修改后的文章更新到数据库中,整个流程以下流程图。
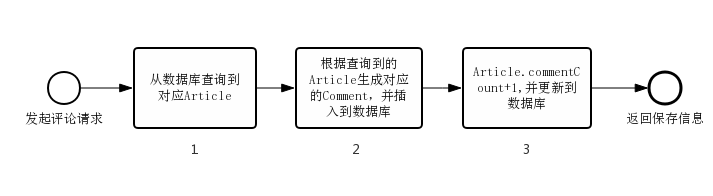
在这个流程中有个问题,当有多个用户同时并发评论时,他们同时进入步骤1中拿到Article,而后插入对应的Comment,最后在步骤3中更新评论数量保存到数据库。只是因为他们是同时在步骤1拿到的Article,因此他们的Article.commentCount的值相同,那么在步骤3中保存的Article.commentCount+1也相同,那么原来应该+3的评论数量,只加了1。
咱们用测试用例代码试一下
@RunWith(SpringRunner.class)
@SpringBootTest(classes = LockAndTransactionApplication.class, webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class CommentControllerTests {
@Autowired
private TestRestTemplate testRestTemplate;
@Test
public void concurrentComment() {
String url = "http://localhost:9090/comment";
for (int i = 0; i < 100; i++) {
int finalI = i;
new Thread(() -> {
MultiValueMap<String, String> params = new LinkedMultiValueMap<>();
params.add("articleId", "1");
params.add("content", "测试内容" + finalI);
String result = testRestTemplate.postForObject(url, params, String.class);
}).start();
}
}
}
复制代码
这里咱们开了100个线程,同时发送评论请求,对应的文章id为1。
在发送请求前,数据库数据为
select * from article
复制代码

select count(*) comment_count from comment
复制代码
发送请求后,数据库数据为
select * from article
复制代码
select count(*) comment_count from comment
复制代码
明显的看到在article表里的comment_count的值不是100,这个值不必定是我图里的14,可是必然是不大于100的,而comment表的数量确定等于100。
这就展现了在文章开头里提到的并发问题,这种问题其实十分的常见,只要有相似上面这样评论功能的流程的系统,都要当心避免出现这种问题。
下面就用实例展现展现如何经过悲观锁和乐观锁防止出现并发数据问题,同时给出SQL方案和JPA自带方案,SQL方案能够通用“任何系统”,甚至不限语言,而JPA方案十分快捷,若是你刚好用的也是JPA,那就能够简单的使用上乐观锁或悲观锁。最后也会根据业务比较一下乐观锁和悲观锁的一些区别
悲观锁解决并发问题
悲观锁顾名思义就是悲观的认为本身操做的数据都会被其余线程操做,因此就必须本身独占这个数据,能够理解为”独占锁“。在java中synchronized和ReentrantLock等锁就是悲观锁,数据库中表锁、行锁、读写锁等也是悲观锁。
利用SQL解决并发问题
行锁就是操做数据的时候把这一行数据锁住,其余线程想要读写必须等待,但同一个表的其余数据仍是能被其余线程操做的。只要在须要查询的sql后面加上for update,就能锁住查询的行,特别要注意查询条件必需要是索引列,若是不是索引就会变成表锁,把整个表都锁住。
如今在原有的代码的基础上修改一下,先在ArticleRepository增长一个手动写sql查询方法。
public interface ArticleRepository extends CrudRepository<Article, Long> {
@Query(value = "select * from article a where a.id = :id for update", nativeQuery = true)
Optional<Article> findArticleForUpdate(Long id);
}
复制代码
而后把CommentService中使用的查询方法由原来的findById改成咱们自定义的方法
public class CommentService {
...
public void postComment(Long articleId, String content) {
// Optional<Article> articleOptional = articleRepository.findById(articleId);
Optional<Article> articleOptional = articleRepository.findArticleForUpdate(articleId);
...
}
}
复制代码
这样咱们查出来的Article,在咱们没有将其提交事务以前,其余线程是不能获取修改的,保证了同时只有一个线程能操做对应数据。
如今再用测试用例测一下,article.comment_count的值一定是100。
利用JPA自带行锁解决并发问题
对于刚才提到的在sql后面增长for update,JPA有提供一个更优雅的方式,就是@Lock注解,这个注解的参数能够传入想要的锁级别。
如今在ArticleRepository中增长JPA的锁方法,其中LockModeType.PESSIMISTIC_WRITE参数就是行锁。
public interface ArticleRepository extends CrudRepository<Article, Long> {
...
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select a from Article a where a.id = :id")
Optional<Article> findArticleWithPessimisticLock(Long id);
}
复制代码
一样的只要在CommentService里把查询方法改成findArticleWithPessimisticLock(),再测试用例测一下,确定不会有并发问题。并且这时看一下控制台打印信息,发现实际上查询的sql仍是加了for update,只不过是JPA帮咱们加了而已。
乐观锁解决并发问题
乐观锁顾名思义就是特别乐观,认为本身拿到的资源不会被其余线程操做因此不上锁,只是在插入数据库的时候再判断一下数据有没有被修改。因此悲观锁是限制其余线程,而乐观锁是限制本身,虽然他的名字有锁,可是实际上不算上锁,只是在最后操做的时候再判断具体怎么操做。
乐观锁一般为版本号机制或者CAS算法
利用SQL实现版本号解决并发问题
版本号机制就是在数据库中加一个字段看成版本号,好比咱们加个字段version。那么这时候拿到Article的时候就会带一个版本号,好比拿到的版本是1,而后你对这个Article一通操做,操做完以后要插入到数据库了。发现哎呀,怎么数据库里的Article版本是2,和我手里的版本不同啊,说明我手里的Article不是最新的了,那么就不能放到数据库了。这样就避免了并发时数据冲突的问题。
因此咱们如今给article表加一个字段version
article 文章表
| 字段 | 类型 | 备注 |
|---|---|---|
| version | INT DEFAULT 0 | 版本号 |
而后对应的实体类也增长version字段
@Data
@Entity
public class Article {
...
private Long version;
}
复制代码
接着在ArticleRepository增长更新的方法,注意这里是更新方法,和悲观锁时增长查询方法不一样。
public interface ArticleRepository extends CrudRepository<Article, Long> {
@Modifying
@Query(value = "update article set comment_count = :commentCount, version = version + 1 where id = :id and version = :version", nativeQuery = true)
int updateArticleWithVersion(Long id, Long commentCount, Long version);
}
复制代码
能够看到update的where有一个判断version的条件,而且会set version = version + 1。这就保证了只有当数据库里的版本号和要更新的实体类的版本号相同的时候才会更新数据。
接着在CommentService里稍微修改一下代码。
// CommentService
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
...
int count = articleRepository.updateArticleWithVersion(article.getId(), article.getCommentCount() + 1, article.getVersion());
if (count == 0) {
throw new RuntimeException("服务器繁忙,更新数据失败");
}
// articleRepository.save(article);
}
复制代码
首先对于Article的查询方法只须要普通的findById()方法就行不用上任何锁。
而后更新Article的时候改用新加的updateArticleWithVersion()方法。能够看到这个方法有个返回值,这个返回值表明更新了的数据库行数,若是值为0的时候表示没有符合条件能够更新的行。
这以后就能够由咱们本身决定怎么处理了,这里是直接回滚,spring就会帮咱们回滚以前的数据操做,把此次的全部操做都取消以保证数据的一致性。
如今再用测试用例测一下
select * from article
复制代码
select count(*) comment_count from comment
复制代码
如今看到Article里的comment_count和Comment的数量都不是100了,可是这两个的值一定是同样的了。由于刚才咱们处理的时候假如Article表的数据发生了冲突,那么就不会更新到数据库里,这时抛出异常使其事务回滚,这样就能保证没有更新Article的时候Comment也不会插入,就解决了数据不统一的问题。
这种直接回滚的处理方式用户体验比较差,一般来讲若是判断Article更新条数为0时,会尝试从新从数据库里查询信息并从新修改,再次尝试更新数据,若是不行就再查询,直到可以更新为止。固然也不会是无线的循环这样的操做,会设置一个上线,好比循环3次查询修改更新都不行,这时候才会抛出异常。
利用JPA实现版本现解决并发问题
JPA对悲观锁有实现方式,乐观锁天然也是有的,如今就用JPA自带的方法实现乐观锁。
首先在Article实体类的version字段上加上@Version注解,咱们进注解看一下源码的注释,能够看到有部分写到:
The following types are supported for version properties: int, Integer, short, Short, long, Long, java.sql.Timestamp.
注释里面说版本号的类型支持int, short, long三种基本数据类型和他们的包装类以及Timestamp,咱们如今用的是Long类型。
@Data
@Entity
public class Article {
...
@Version
private Long version;
}
复制代码
接着只须要在CommentService里的评论流程修改回咱们最开头的“会触发并发问题”的业务代码就好了。说明JPA的这种乐观锁实现方式是非侵入式的。
// CommentService
public void postComment(Long articleId, String content) {
Optional<Article> articleOptional = articleRepository.findById(articleId);
...
article.setCommentCount(article.getCommentCount() + 1);
articleRepository.save(article);
}
复制代码
和前面一样的,用测试用例测试一下可否防止并发问题的出现。
select * from article
复制代码
select count(*) comment_count from comment
复制代码
一样的Article里的comment_count和Comment的数量也不是100,可是这两个数值确定是同样的。看一下IDEA的控制台会发现系统抛出了ObjectOptimisticLockingFailureException的异常。
这和刚才咱们本身实现乐观锁相似,若是没有成功更新数据则抛出异常回滚保证数据的一致性。若是想要实现重试流程能够捕获ObjectOptimisticLockingFailureException这个异常,一般会利用AOP+自定义注解来实现一个全局通用的重试机制,这里就是要根据具体的业务状况来拓展了,想要了解的能够自行搜索一下方案。
悲观锁和乐观锁比较
悲观锁适合写多读少的场景。由于在使用的时候该线程会独占这个资源,在本文的例子来讲就是某个id的文章,若是有大量的评论操做的时候,就适合用悲观锁,不然用户只是浏览文章而没什么评论的话,用悲观锁就会常常加锁,增长了加锁解锁的资源消耗。
乐观锁适合写少读多的场景。因为乐观锁在发生冲突的时候会回滚或者重试,若是写的请求量很大的话,就常常发生冲突,常常的回滚和重试,这样对系统资源消耗也是很是大。
因此悲观锁和乐观锁没有绝对的好坏,必须结合具体的业务状况来决定使用哪种方式。另外在阿里巴巴开发手册里也有提到:
若是每次访问冲突几率小于 20%,推荐使用乐观锁,不然使用悲观锁。乐观锁的重试次 数不得小于 3 次。
阿里巴巴建议以冲突几率20%这个数值做为分界线来决定使用乐观锁和悲观锁,虽说这个数值不是绝对的,可是做为阿里巴巴各个大佬总结出来的也是一个很好的参考。
- 1. 悲观锁和乐观锁
- 2. 乐观锁和悲观锁
- 3. 悲观锁 和 乐观锁
- 更多相关文章...
- • Hibernate悲观锁 - Hibernate教程
- • Hibernate乐观锁 - Hibernate教程
- • 漫谈MySQL的锁机制
- • Spring Cloud 微服务实战(三) - 服务注册与发现
-
每一个你不满意的现在,都有一个你没有努力的曾经。